 本章对于机器学习任务的一些通用框架做了介绍,包括经典架构以及AutoML。
本章对于机器学习任务的一些通用框架做了介绍,包括经典架构以及AutoML。
12. 机器学习框架
12.1 通用机器学习框架
12.1.1 典型场景浅析
机器学习的应用场景几乎涵盖了生活中的各个领域,最典型的场景有:
面向C端的互联网场景 典型的有搜索、推荐、广告、风控,特点是:
1、数据量巨大,每天的样本量在亿~百亿量级,甚至更高,这个规模对数据处理有极大地挑战,基本都需要分布式存储和计算系统的支持,例如:Hadoop、Spark平台。
2、模型复杂、特征维度高、可解释性差,由于有丰富的数据(如:文本、图像、点击行为、浏览行为、下单行为等等),所以在此基础上可以提取及交叉生成大量特征,例如,在计算广告中,广告本身的素材、广告的位置、广告的曝光量、广告的出价、用户的Demographic画像、用户的Geographic画像、用户的浏览路径、用户的点击行为、用户所处上下文、用户使用浏览器、广告+用户+上下文环境交叉产生的各种特征。机器学习本质上只揭示相关性不得出因果性,最终的模型每个特征会对这个相关性起到一定作用,所谓三个臭皮匠顶一个诸葛亮,所以理论上数据量越大、特征越丰富、反馈越及时,模型效果越好。当然,正是为了效果而使用了大量类似DNN的模型,导致可解释性变差。
3、在线实时性、并发性要求高,包含两方面:模型效果的实时性和系统响应的实时性。当用户行为能更快的反馈到模型中时,模型出现好效果的概率越大,一方面模型可以实时学习,一方面特征可以实时改变,这样通过反馈数据可以迅速调整模型,就像人一样,正常来说都是吃一堑长一智,通过发生行为->得到结果->进行调整->发生行为......的不断循环而进步。成功的互联网产品流量较高且对用户体验要求很高,势必要求请求量很高时系统依然能保证实时性,所以系统返回结果到用户面前一般都是毫秒级的,这就需要一方面系统并发性要好,一方面特征处理速度要快,另一方面模型单机Inference速度要够快。
4、离线模型训练时效性要求高,即使采用Online Learning,也需要离线模型的支持,一般为保证模型质量,每个模型每天至少训练一次,在特征维度和样本量这么高且实验模型数量可观的场景下(最典型的如:DNN,动辄上千万、上亿、上百亿的参数规模,学一次成本又高,产生的模型又大),势必会影响模型训练时间,甚至量大了模型训练都跑不起来,而抽样又会破坏数据的真实分布,所以对离线大规模机器学习平台的要求就很高了。
5、数据采集和处理速度要求高,前面也说了,内容给用户展示后势必会产生用户反馈,这个反馈日志要尽快的解析、存储和处理,并及时推给模型训练或特征更新使用,当然这里对日志丢失的容忍度相对较高。
6、模型线上试错成本相对较低,以广告为例,利用E&E算法,通过损失曝光机会进而损失部分收益来测算模型效果,但由于反馈时间短,可以很快的做调整。
面向B端的场景
对于大B端,一类是拥有和互联网C端类似场景的B端,数据量大、样本量大、实时性和并发性高,只是特征维度未必有那么高,但带来的系统挑战一点都不低,另一类是平台提供方,例如阿里云、腾讯云,更多的是通用工程层面和产品层面的挑战。 对于中小B端,一类会上云,利用平台方提供的IaaS、PaaS甚至SaaS,另一类会搭建自己的系统,典型的应用如面向汽车金融、融资租赁的风控平台,其特点是:
1、数据量中等但单条数据价值高,例如,假设汽车融资租赁的客单价为7w,每年卖出100w辆车,以融后资产质量数据为例,原始标注数据量为百万级别,远远小于传统互联网数据量,但极端的看,每条数据是花了7w的成本付出验证出来的。
2、模型相对复杂,特征维度一般,可解释性强,受限于数据量和场景,风控模型特征维度一般不高,但对可解释性要求很高,一方面风控业务向销售以及销售要向客户解释,另一方面风控业务要通过这种解释性反向影响风控政策或调整公司整体策略。
3、比较重视外部合规数据合作,由于平台本身的数据量及场景限制,需要寻找外部数据合作,这种合作可以是数据粒度的也可以是模型粒度的,但一定要保证所有合作数据的授权、获取是合规的,以及用户隐私能够被很好的保护,近年来的联邦学习可能是未来一种主流合作模式。
4、数据效果反馈滞后,对欺诈容忍度很低,金融资产总有个还款周期,例如典型的以“月”为周期,意味着资产被放出后过了1个月才能看到资产质量,如果发生欺诈,则第1~3个MOB就可能会批量出现问题,如果出现逾期也至少要等待1个月,所以客户真实反馈很滞后。
5、模型试错成本高,由于客单价较高,采用传统E&E算法的试错成本会很高,所以其实用性一般较差,只有小额现金贷勉强可以使用此类方法,所以离线模型训练时需要想各种办法尽量模拟真实场景,一类重要的方法是拒绝推断,另一类是订单回放对比。另外模型测试指标要求更高,以AUC为例,在计算广告场景,AUC达到0.8就可以放心上去试跑了,在汽车消费风控场景,AUC超过0.85都心中打鼓。
6、系统实时性、并发性要求一般但稳定性要求更高,一方面业务单量没有那么大,并发性很低,另一方面由于使用外部数据,系统响应时间达到s级都很常见,但由于一个单子就影响到一个销售的业绩和前端竞争,所以稳定性很重要,要尽量保证系统不卡壳。
12.1.2 系统流程
一般的建模系统流程如下: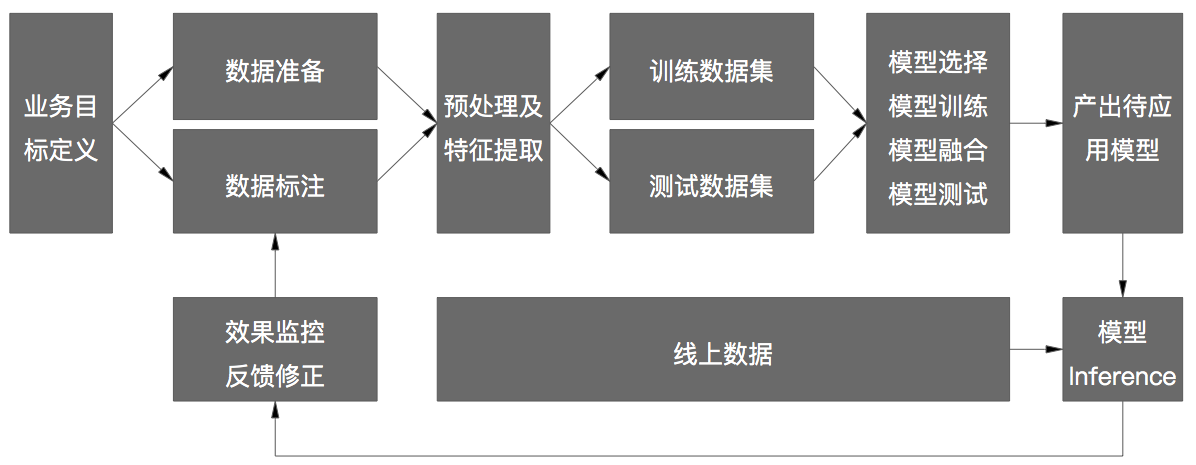
以广告和推荐系统为例:
数据准备和数据标注 样本生成分两部分:
1、离线部分,主要通过收集用户线上行为日志、已上线模型特征日志数据、业务日志数据而来,实时性要求低,一般会通过日志Stream服务收集到集群(如:hadoop集群)并持久化,所以日志设计非常关键,一方面是内容格式,要求扩展性要好,表达信息清晰而不易混淆,例如:已上线的不同版本模型的特征直接会被记录到日志中,如何区分模型、区分版本而又不会占用过多位是个有讲究的工作;另一方面是传输格式,常用的有非二进制的Xml、Json等和二进制的Pb、Thrift等,前者的好处是可读性好方便调试,但日志内容如果较为复杂传输成本高,隐私安全性低,后者反之,一般来说我们会采用后者。
2、在线部分,除了用日志Stream收集服务外一般还会辅以实时计算服务,实时收集和解析日志并做特征加工,一方面用于更新线上模型的离线特征,一方面为online learning算法提供实时特征,另一方面辅助类似频次控制这样的线上策略实施。
3、数据标注,对标注定义比较简单的场景,可以做到实时且无需人工介入的标注,例如:用户的点击行为、成交行为等,而对于图像分类、分割等复杂场景,需要专门平台甚至专人去做标注。由于目前机器学习的主流依然是监督学习,所以期待未来某天能从“人工+智能”过渡到人工智能,让机器去做人类做不了的事儿。
数据预处理及特征工程 我们收集到日志数据并做解析和简单处理后,一方面需要对数据做进一步清洗,例如:缺失值处理、丢弃、数据质检等,另一方面就是利用特征工程生成各种特征以备模型使用,特征要么是算法人员根据先验知识不断做实验打磨出来,要么利用特征生成算法(如:FM系列)或工具(如:FeatureTools)辅助生成,纯粹的End to End并不普遍,尤其是传统机器学习覆盖的场景,这个与原始特征的结构化复杂度有关,比如:图像识别,其原始特征是像素,很单一;一般的自然语言处理,其原子特征是字或词,相对单一,而像CTR预估的传统机器学习场景,其原始特征千差万别。
模型训练和融合 依据不同业务目标定义样本和构建模型,利用离线单机或并行机器学习工具训练模型,通过人工先验知识或启发式算法方式调整模型参数,得到最终离线模型。由于每个模型有各自特长,如:有的善于处理分类特征、有的则是连续特征、有的是文本特征等等,很多情况下需要融合这些模型的效果到一个大模型中,相应的可能带来效率上的挑战。当模型满足一定效果指标后(如,AUC)即可有资格到线上做实验,通过AB Test方式辅以E&E策略做线上测试,效果好者逐渐扩大流量。
模型线上inference 真正做线上模型预测的服务,一方面取特征或生成特征,另一方面执行y=f(x)并返回结果,同步,日志系统会实时收集效果反馈。
12.1.3 系统架构
一个典型的机器学习框架如下:

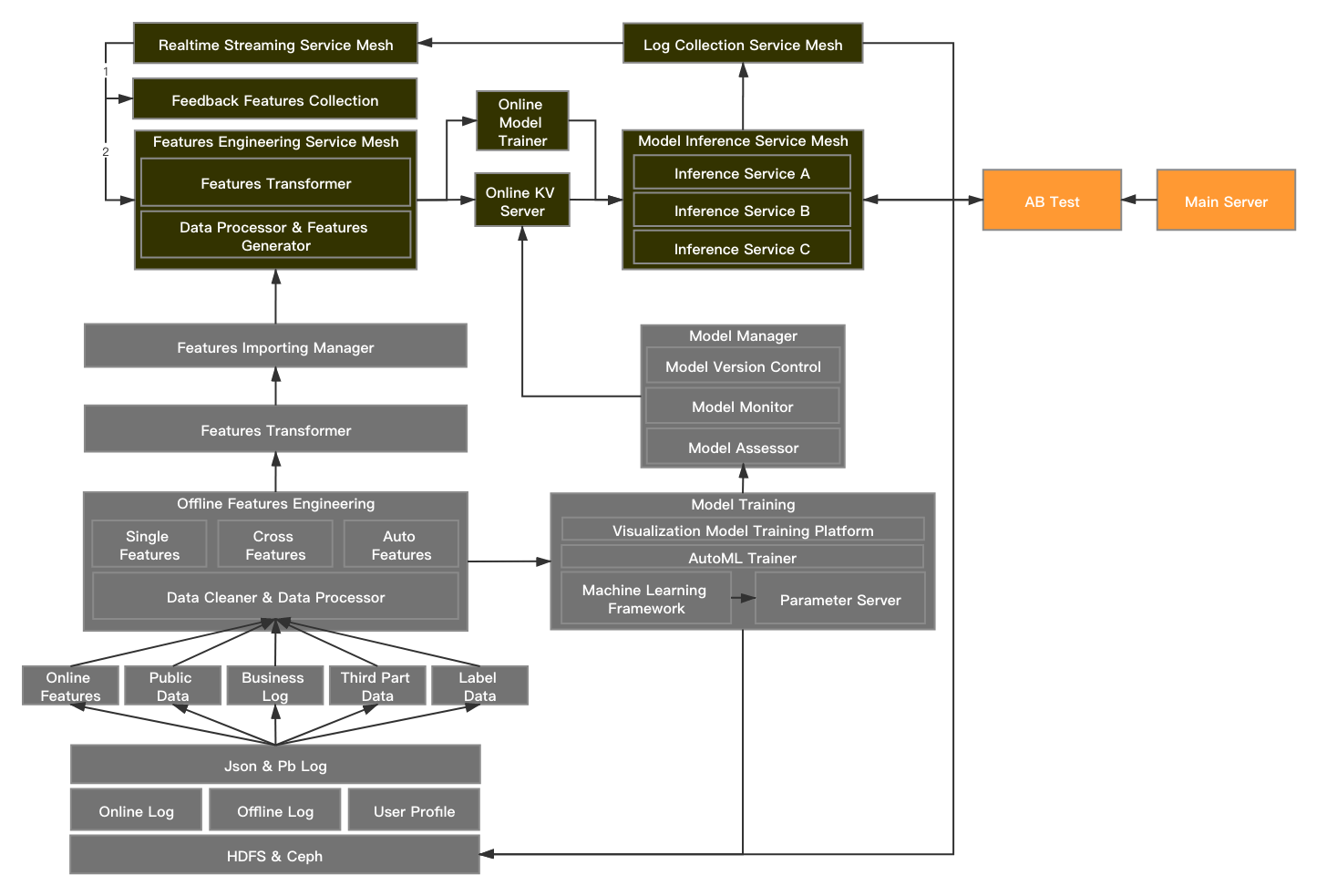
- 离线日志,数据存储在HDFS等分布式存储介质上,方便使用类似MapReduce方式做离线大规模数据处理,还可以复用自己或其他团队产生的用户画像信息作为特征。
- 离线特征工程,对数据做清洗和预处理后,可以利用单机或集群方式生成特征,从类型上说包括计数统计类特征、聚合类特征、单或交叉的Target Encoding特征、Embedding特征、图像特征、利用AutoML技术生成的组合特征等等,从时间切片上说包括实时特征、近实时特征、时间序列特征、T+1特征、T+N特征等等,生成的特征通过导出工具推送到线上特征工程微服务供大家使用,特征层面各个模型尽量复用。
- 在线特征工程,利用实时流微服务收集到的日志大多是用户反馈行为类日志,这部分时效性比较强的行为日志适合做实时特征,例如,用户点击了某个内容,同一地址用户短时集中点击了某个内容等等,特征生成后会自动推送到线上特征工程微服务,随后依照不同版本自动流入高响应的kv类存储介质中。
- 模型训练,以成熟的大规模机器学习框架及其他成熟机器学习框架为底层框架,中层提供常用算法组件和AutoML训练器,上层提供可视化模型构建平台,让使用者相对低成本做模型。对于大规模数据做训练,一般少不了参数服务器,其大致原理可以看这里。
- 模型管理器,这里对模型的参数配置、版本、效果做管理和监控,训练好的模型会被推送到线上高响应的kv类存储介质中。
- 模型应用,以微服务方式,对每个版本的模型提供Inference服务,服务间互相独立且可横向扩展,既保证了稳定性又保证了并发性。
- AB test,应用方的AB测试服务会根据实验策略不同实时配置相应的模型应用。
12.2 NNI AutoML框架介绍
12.2.1 AutoML综述
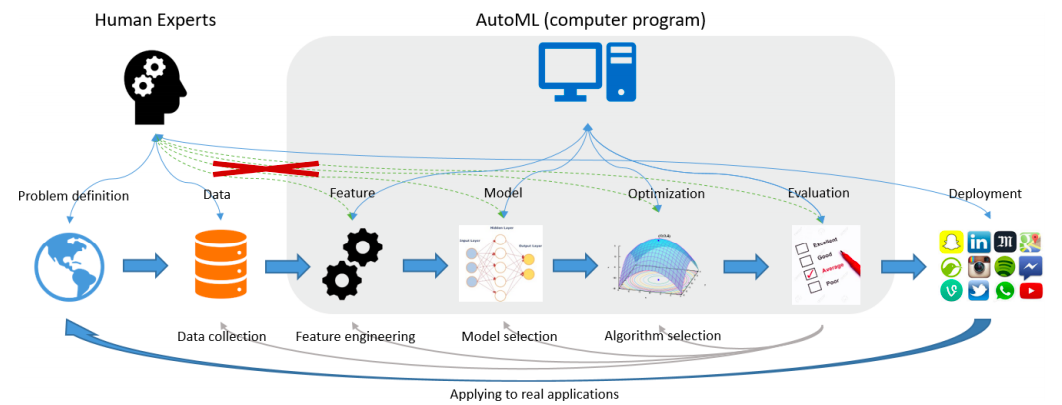
上图选自《Taking the Human out of Learning Applications:A Survey on Automated Machine Learning》一文。 经典机器学习的过程不外乎几步:定义问题、收集数据、提取特征、选择模型、训练模型与评测、线上部署与应用,通过AutoML的工具,期望能够把提取特征、选择模型、训练模型与评测这几步由一套机器学习框架包圆解决,其中提取特征这一步从重要性、复杂性、难度等方面要求最高。 形式化定义AutoML如下:
\[ \begin{eqnarray} \label{eq} \mathop{max}\limits_{config}&\quad&机器学习工具的效率和效果 \nonumber \\ s.t.&\quad&没有或少做人工干预 \nonumber \\ &\quad&可负担的有限计算资源 \nonumber \end{eqnarray} \]
其框架大致如下: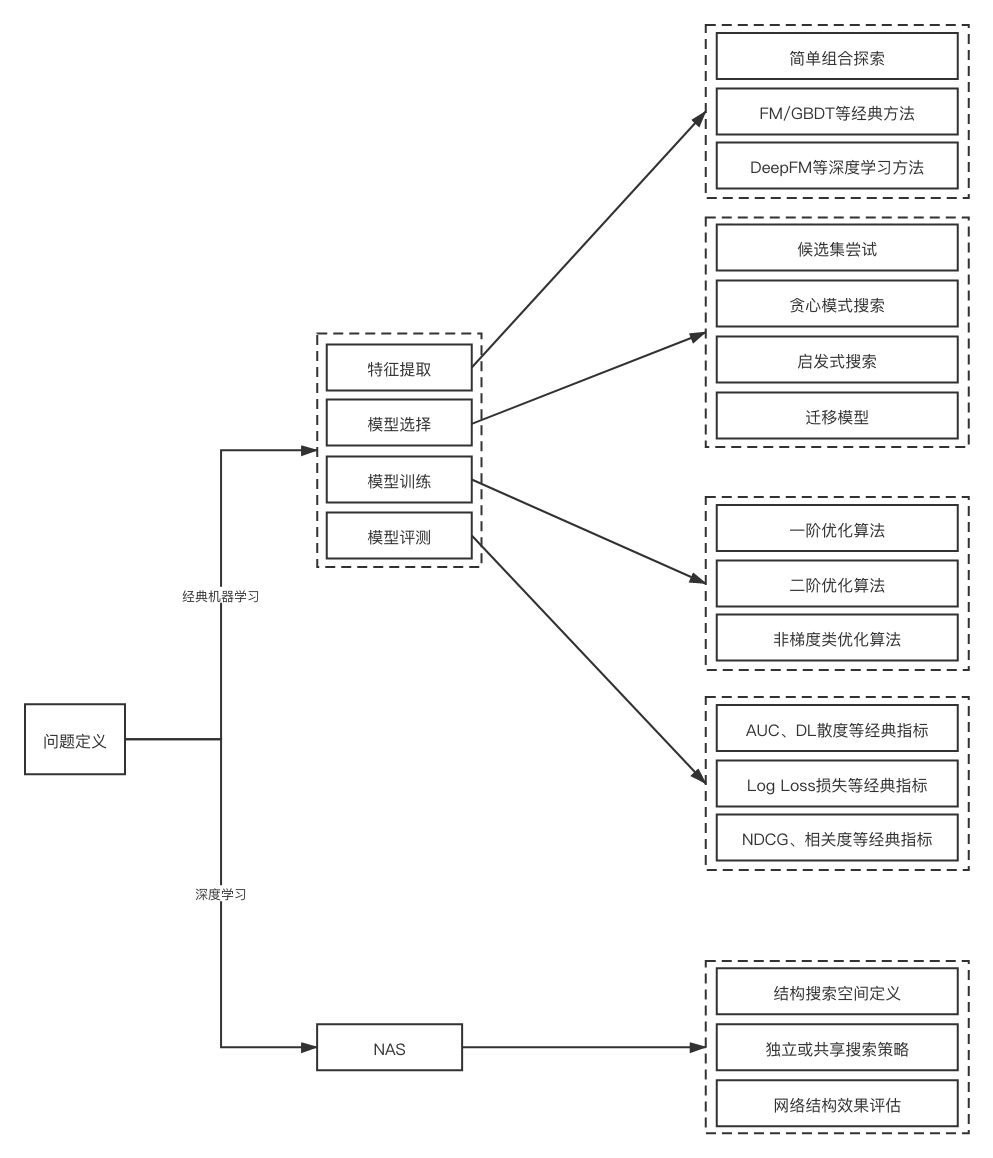
在经典机器学习问题中:
特征提取
1、简单组合搜索,可以采用事先定义简单组合策略,通过排列组合方式做特征生成,特征生成大多基于统计类方法,经典的工具如FeatureTools,例如:
![]()
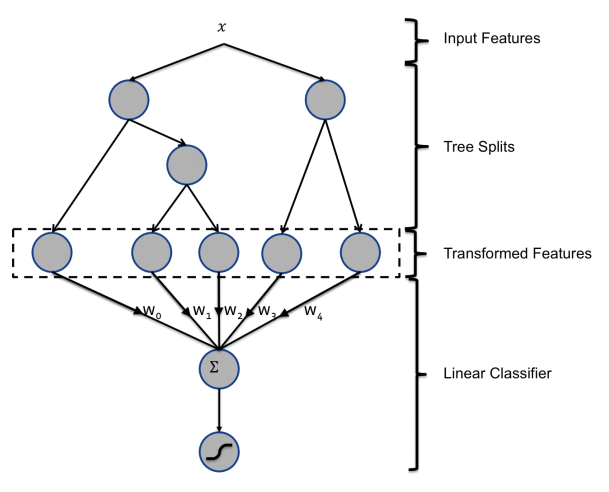
2、经典机器学习方法,利用FM、GBDT这类非线性模型作自动特征组合能够产生二阶以上特征,也可以做到特征提取+模型训练一体化,经典的论文如:《Practical Lessons from Predicting Clicks on Ads at Facebook》。
![]()
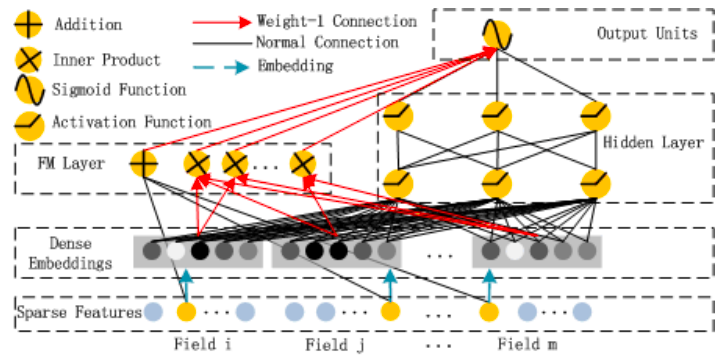
3、DeepFM等深度学习方法,利用神经网络做更复杂特征的生成,也可以做到特征提取+模型训练一体化,但需要注意tradeoff效率和效果。 以下是DeepFM的经典结构,左边的FM部分是经典的因式分解机模式,可以高效的发现一阶和二阶特征,右边是深度网络部分,是一个前馈神经网络,用来生成二阶以上高阶特征,由于类似CTR预估问题的特征一般维度比较高且特征稀疏,大量类别特征与连续特征混排,所以神经网络的输入层一般会通过Embedding方式处理原始特征。
![]()
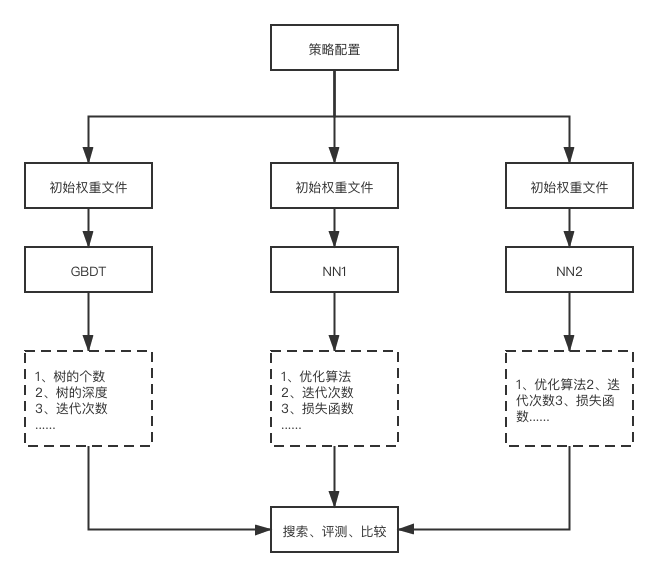
模型选择
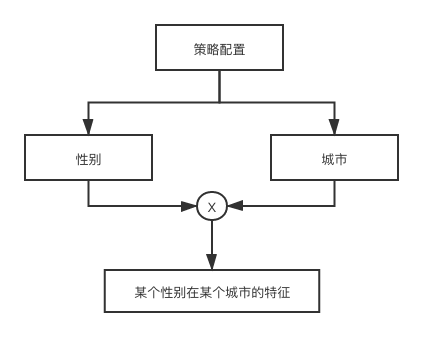
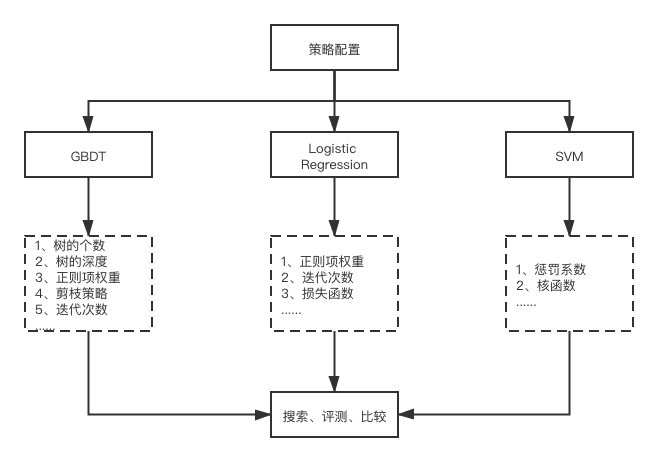
1、不管候选集、贪心还是启发式方法,都需要定义搜索空间,在有限搜索空间内选择并训练不同模型,同时做参数搜索调优,最终得到效果最好的模型,一般框架如下:
![]()
2、直接指定模型,但使用别人已经训练好的不同权重做初始化,即Transfer Learning,一般框架
![]()
模型训练
1、基于泰勒展开式的一阶和二阶优化算法,用来做目标函数最优化求解,代表算法:基于梯度的SGD、GD等和基于Hessian矩阵的L-BFGS等,详情可以见第四章 最优化原理
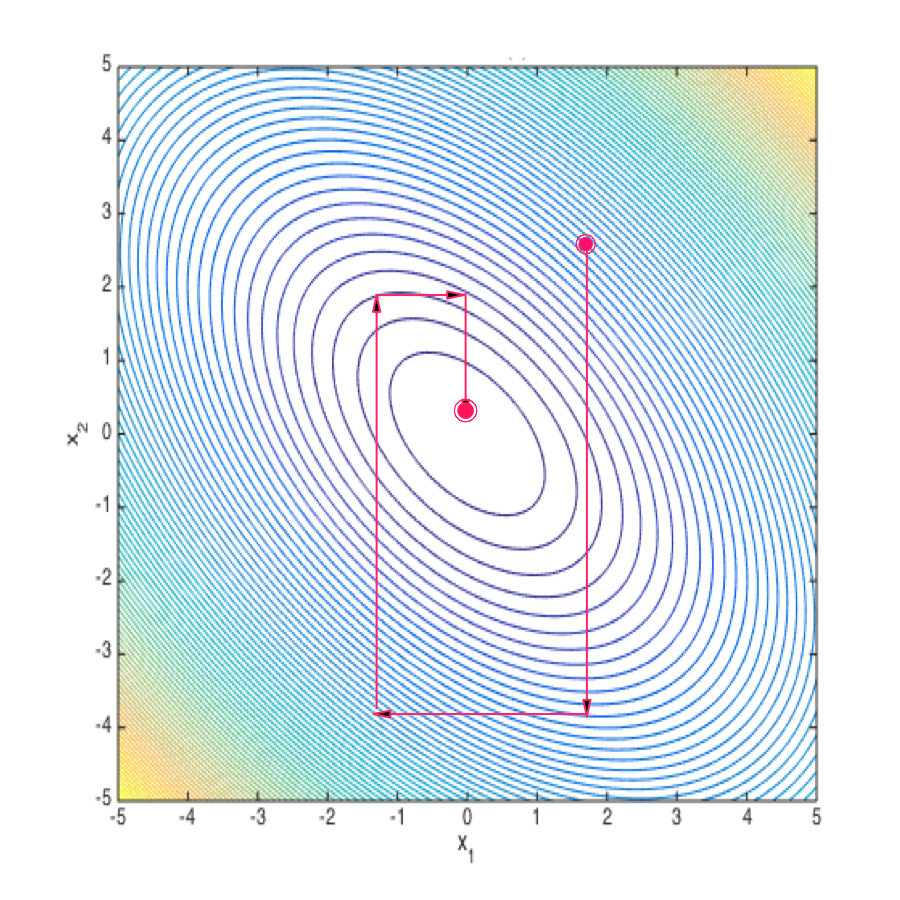
2、非梯度优化算法,典型的有: 坐标下降法(Coordinate Descent),属于一种非梯度优化的方法,它的每步迭代会沿某一个坐标的方向做一维搜索,通过切换不同坐标来求得目标函数局部最优解,可以看做是把一个优化问题分解为一组优化问题,直观的看:
![]()
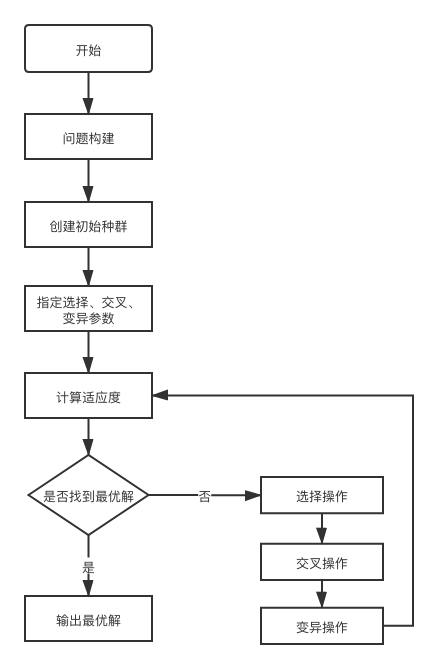
遗传算法,也是一种非梯度优化方法,更多的是利用生物进化思想做最优化求解,一般框架如下:
![]()
模型评测
1、监督学习问题 对于分类问题,常用AUC、KS、F-Measure等,对于回归问题常用MSE、RMSE、MAE等。
2、非监督学习问题 开放性的无监督学习,效果评价一般看实际应用问题情况,也比较需要人工做评测。
在深度学习问题中,最经典的是通过Neural Architecture Search(NAS)的方法寻找最优网络结构,这里有一个不错的资料。
12.2.2 NNI框架介绍
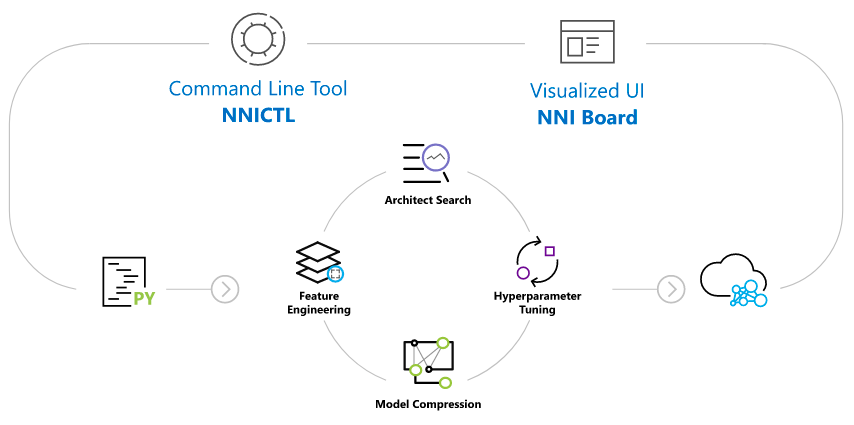
NNI概述 NNI是18年MSRA发布的轻量级AutoML开源框架,Python编写,主要支持自动特征工程、NAS、最优模型参数搜索、模型压缩几个方面。整体设计和代码上比较简洁,上手难度比较低,支持可视化模式和命令行模式,大体情况如下:
![]()
1、机器学习框架方面,它基本支持市面上所有主流的框架:PyTorch、TensorFlow、Keras、MXNet、Caffe2、CNTK、Spark MLlib、Chainer、Theano。
2、机器学习库方面,工业界用的比较多的它都支持,如:Scikit-learn、XGBoost、CatBoost、LightGBM。
3、模型参数搜索方面,它支持: 暴力搜索算法,包括:Random Search、Grid Search、Batch; 启发式搜索算法,包括:Naïve Evolution、Anneal、Hyperband、PBT; 贝叶斯优化算法,包括:BOHB、TPE、SMAC、Metis、Gaussian Process; 基于强化学习的算法,包括:PPO。
4、NAS方面,几乎支持所有主流算法:ENAS、DARTS、P-DARTS、CDARTS、SPOS、ProxylessNAS、Network Morphism、TextNAS。
5、模型压缩方面 模型剪枝:AGP Pruner、Slim Pruner、FPGM Pruner; 模型量化:QAT Quantizer、DoReFa Quantizer。
6、特征工程方面,支持基于梯度搜索的算法和基于LightGBM(一种GBDT实现)的算法。在自动特征工程方面,整体偏弱。
7、迭代停止算法方面,支持Medianstop和Curve Fitting,整体上够用。
8、部署方面,支持本地化部署、远程集群部署、基于K8s的部署。
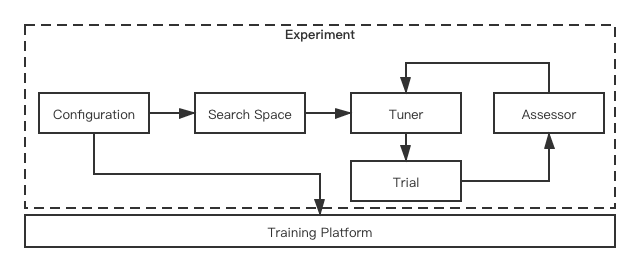
逻辑框架
![]()
1、Configuration,NNI通过配置文件指定各种策略和运行环境,一个典型的配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32authorName: zhanglei
experimentName: auto-catboost
# trial的最大并发数
trialConcurrency: 10
# 实验最多执行时间
maxExecDuration: 1h
# Trial的个数
maxTrialNum: 1000
# 训练平台,可选项有: local, remote, pai
trainingServicePlatform: local
# 参数或结构搜索空间定义
searchSpacePath: search_space.json
# 取值为false,则上面的搜索空间json文件需要定义
# 取值为true,则需要在代码中以Annotation方式加入搜索空间定义,例如:
# ......
# """@nni.variable(nni.choice(0.1, 0.5), name=dropout_rate)"""
# dropout_rate = 0.5
# ......
# 表示dropout_rate这个变量有两个取值选择:0.1或0.5
useAnnotation: false
tuner:
# 参数或结构搜索策略定义,可选项有:
# TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner, SMAC等,有些需要单独安装
builtinTunerName: TPE
classArgs:
# 选择求解目标函数最大值还是最小值: maximize, minimize
optimize_mode: maximize
trial:
# Trial代码所在目录位置、可执行文件及GPU配置
command: python3 catboost_trainer.py
codeDir: .
gpuNum: 02、Search Space,搜索空间定义,一种方式是通过一个json文件定义,一种方式是代码里加Annotation,一个典型的例子如下:
_type为choice,表示参数选择范围是_value指定的候选参数; _type为randint,表示参数选择范围是_value指定的上下界之间的整数; _type为uniform,表示参数选择范围是_value指定的上下界之间通过均匀分布得到的数; _type为uniform,表示参数选择范围是_value指定的上下界,并用均匀分布生成的参数,此外还有quniform、loguniform、qloguniform、normal、qnormal、lognormal、qlognormal几种分布。1
2
3
4
5
6
7
8
9
10
11{
"num_leaves":{"_type":"randint","_value":[20, 150]},
"learning_rate":{"_type":"choice","_value":[0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5]},
"bagging_fraction":{"_type":"uniform","_value":[0.5, 1.0]},
"feature_fraction":{"_type":"uniform","_value":[0.5, 1.0]},
"reg_alpha":{"_type":"choice","_value":[0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]},
"reg_lambda":{"_type":"choice","_value":[0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]},
"lambda_l1":{"_type":"uniform","_value":[0, 10]},
"lambda_l2":{"_type":"uniform","_value":[0, 10]},
"bagging_freq":{"_type":"choice","_value":[1, 2, 4, 8, 10]}
}3、Tuner,是参数或结构的搜索策略,利用它可以为每个Trial生成相应的参数集合,除了内置的Tuner算法外,也可以自定义Tuner,例如:
使用时需要在配置文件的tuner属性中指定,例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23from nni.tuner import Tuner
# 自定义的Tuner需要继承Tuner基类
class CustomizedTuner(Tuner):
def __init__(self, ...):
...
def receive_trial_result(self, parameter_id, parameters, value, **kwargs):
'''
返回一个Trial的最终效果指标,可以是字典(但必须由默认key),也可以是某个值
parameter_id: int类型
parameters: 由'generate_parameters()'函数生成
'''
# 你的代码实现
...
def generate_parameters(self, parameter_id, **kwargs):
'''
生成一个Trial所需的参数,并以序列化方式存储
parameter_id: int类型
'''
# 你的代码实现.
return your_parameters
...1
2
3
4
5
6
7
8
9tuner:
# 代码目录
codeDir: /home/abc/mytuner
# 自定义Tuner类名
classFileName: my_customized_tuner.py
className: CustomizedTuner
# 自定义Tuner的构造函数参数指定
classArgs:
arg1: value14、Trial,是一次模型学习的尝试,它使用Tuner生成的参数初始化模型,而后做模型训练,并返回最终训练效果,一个CatBoost做AutoML的例子如下:
1)、定义CatBoost类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161# coding=UTF-8
"""
class CatBoostModel
"""
import random
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.metrics import roc_auc_score
import gc
import catboost as cb
from catboost import *
import numpy as np
import pandas as pd
from tools.feature_utils import cat_fea_cleaner
class CatBoostModel():
def __init__(self, **kwargs):
assert kwargs['catboost_params']
assert kwargs['eval_ratio']
assert kwargs['early_stopping_rounds']
assert kwargs['num_boost_round']
assert kwargs['cat_features']
assert kwargs['all_features']
self.catboost_params = kwargs['catboost_params']
self.eval_ratio = kwargs['eval_ratio']
self.early_stopping_rounds = kwargs['early_stopping_rounds']
self.num_boost_round = kwargs['num_boost_round']
self.cat_features = kwargs['cat_features']
self.all_features = kwargs['all_features']
self.selected_features_ = None
self.X = None
self.y = None
self.model = None
def fit(self, X, y, **kwargs):
"""
Fit the training data to FeatureSelector
Paramters
---------
X : array-like numpy matrix
The training input samples, which shape is [n_samples, n_features].
y : array-like numpy matrix
The target values (class labels in classification, real numbers in
regression). Which shape is [n_samples].
catboost_params : dict
Parameters of lightgbm
eval_ratio : float
The ratio of data size. It's used for split the eval data and train data from self.X.
early_stopping_rounds : int
The early stopping setting in lightgbm.
num_boost_round : int
num_boost_round in lightgbm.
"""
self.X = X
self.y = y
X_train, X_eval, y_train, y_eval = train_test_split(self.X,
self.y,
test_size=self.eval_ratio,
random_state=random.seed(41))
catboost_train = Pool(data=X_train, label=y_train, cat_features=self.cat_features, feature_names=self.all_features)
catboost_eval = Pool(data=X_eval, label=y_eval, cat_features=self.cat_features, feature_names=self.all_features)
self.model = cb.train(params=self.catboost_params,
pool=catboost_train,
num_boost_round=self.num_boost_round,
eval_sets=catboost_eval,
early_stopping_rounds=self.early_stopping_rounds)
self.feature_importance = self.get_fea_importance(self.model, self.all_features)
def get_selected_features(self, topk):
"""
Fit the training data to FeatureSelector
Returns
-------
list :
Return the index of imprtant feature.
"""
assert topk > 0
self.selected_features_ = self.feature_importance.argsort()[-topk:][::-1]
return self.selected_features_
def predict(self, X, num_iteration=None):
return self.model.predict(X, num_iteration)
def get_fea_importance(self, clf, columns):
importances = clf.feature_importances_
indices = np.argsort(importances)[::-1]
importance_list = []
for f in range(len(columns)):
importance_list.append((columns[indices[f]], importances[indices[f]]))
print("%2d) %-*s %f" % (f + 1, 30, columns[indices[f]], importances[indices[f]]))
print("another feature importances with prettified=True\n")
print(clf.get_feature_importance(prettified=True))
importance_df = pd.DataFrame(importance_list, columns=['Features', 'Importance'])
return importance_df
def train_test_split(self, X, y, test_size, random_state=2020):
sss = list(StratifiedShuffleSplit(
n_splits=1, test_size=test_size, random_state=random_state).split(X, y))
X_train = np.take(X, sss[0][0], axis=0)
X_eval = np.take(X, sss[0][46], axis=0)
y_train = np.take(y, sss[0][0], axis=0)
y_eval = np.take(y, sss[0][47], axis=0)
return [X_train, X_eval, y_train, y_eval]
def catboost_model_train(self,
df,
finetune=None,
target_name='Label',
id_index='Id'):
df = df.loc[df[target_name].isnull() == False]
feature_name = [i for i in df.columns if i not in [target_name, id_index]]
for i in feature_name:
if i in self.cat_features:
#df[i].fillna(-999, inplace=True)
if df[i].fillna('na').nunique() < 12:
df.loc[:, i] = df.loc[:, i].fillna('na').astype('category')
else:
df.loc[:, i] = LabelEncoder().fit_transform(df.loc[:, i].fillna('na').astype(str))
if type(df.loc[0,i])!=str or type(df.loc[0,i])!=int or type(df.loc[0,i])!=long:
df.loc[:, i] = df.loc[:, i].astype(str)
X_train, X_eval, y_train, y_eval = self.train_test_split(df[feature_name],
df[target_name].values,
self.eval_ratio,
random.seed(41))
del df
gc.collect()
catboost_train = Pool(data=X_train, label=y_train, cat_features=self.cat_features, feature_names=self.all_features)
catboost_eval = Pool(data=X_eval, label=y_eval, cat_features=self.cat_features, feature_names=self.all_features)
self.model = cb.train(params=self.catboost_params,
init_model=finetune,
pool=catboost_train,
num_boost_round=self.num_boost_round,
eval_set=catboost_eval,
verbose_eval=50,
plot=True,
early_stopping_rounds=self.early_stopping_rounds)
self.feature_importance = self.get_fea_importance(self.model, self.all_features)
metrics = self.model.eval_metrics(data=catboost_eval,metrics=['AUC'],plot=True)
print('AUC values:{}'.format(np.array(metrics['AUC'])))
return self.feature_importance, metrics, self.model2)、定义模型训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128# coding=UTF-8
import bz2
import urllib.request
import logging
import os
import os.path
from sklearn.datasets import load_svmlight_file
from sklearn.preprocessing import LabelEncoder
import nni
from sklearn.metrics import roc_auc_score
import gc
import pandas as pd
from models.auto_catboost.catboost_model import CatBoostModel
from tools.feature_utils import write_feature_importance
from feature_engineering.feature_data_processing.dataset_formater import read_columns2list
from tools.feature_utils import name2feature, get_default_parameters, cat_fea_cleaner
from tools.CONST import *
logger = logging.getLogger('auto_catboost')
def trainer_and_tester_run(feature_file_name,
train_file_name,
test_file_name_list,
feature_imp_name):
'''
以批量方式训练CatBoost模型
'''
fea = read_columns2list(feature_file_name, 1)
cat_fea = [item for item in fea if item.startswith('C')]
chunker = pd.read_csv(train_file_name,
sep="\t",
chunksize=10000000,
low_memory=False,
header=0,
usecols=[ColumnType.TARGET_NAME] + fea)
# 从Tuner获得参数
RECEIVED_PARAMS = nni.get_next_parameter()
logger.debug(RECEIVED_PARAMS)
PARAMS = get_default_parameters('catboost')
PARAMS.update(RECEIVED_PARAMS)
logger.debug(PARAMS)
cb = CatBoostModel(catboost_params=PARAMS,
eval_ratio=0.33,
early_stopping_rounds=20,
cat_features=cat_fea,
all_features=fea,
num_boost_round=1000)
logger.debug("The trainning process is starting...")
clf = None
# 数据量太大需要分片训练
for df in chunker:
df = cat_fea_cleaner(df, ColumnType.TARGET_NAME, ColumnType.ID_INDEX, cat_fea)
feature_imp, val_score, clf = \
cb.catboost_model_train(df,
clf,
target_name=ColumnType.TARGET_NAME,
id_index=ColumnType.ID_INDEX)
logger.info(feature_imp)
logger.info(val_score)
write_feature_importance(feature_imp,
feature_file_name,
feature_imp_name, False)
del df
gc.collect()
logger.debug("The trainning process is ended.")
if len(test_file_name_list) == 0:
logger.debug("No testing file is found.")
return
av_auc = 0
for fname in test_file_name_list:
av_auc = av_auc + inference(clf, fea, cat_fea, fname)
av_auc = av_auc/len(test_file_name_list)
nni.report_final_result(av_auc)
def inference(clf, fea, cat_fea, test_file_name):
'''
线上CatBoost模型预测
'''
if not os.path.exists(test_file_name):
logger.error("the file {0} is not exist.".format(test_file_name))
return 0
logger.debug("The testing process is starting...")
try:
df = pd.read_csv(test_file_name,
sep="\t",
header=0,
usecols=[ColumnType.TARGET_NAME] + fea)
df = cat_fea_cleaner(df, ColumnType.TARGET_NAME, ColumnType.ID_INDEX, cat_fea)
y_pred = clf.predict(df[fea])
auc = roc_auc_score(df[ColumnType.TARGET_NAME].values, y_pred)
print("{0}'s auc of prediction:{1}".format(os.path.split(test_file_name)[1], auc))
del df
gc.collect()
logger.debug("The inference process is ended.")
return auc
except ValueError:
logger.error("inference error with file:{0}".format(test_file_name))
return 0
def run_offline():
'''
离线模型训练
'''
base_dir = '/home/liyiran/PycharmProjects/DeepRisk/data/fresh.car/'
train_file_name = base_dir + 'tt'
test_file_name_list = [base_dir + 'outer_test_2019-01.tsv']
feature_file_name = base_dir + 'features.dict'
feature_imp_name = base_dir + 'features.imp'
trainer_and_tester_run(feature_file_name, train_file_name, test_file_name_list, feature_imp_name)
if __name__ == '__main__':
run_online()5、Assessor,使用提前停止迭代策略评估Trial是否可以结束训练。
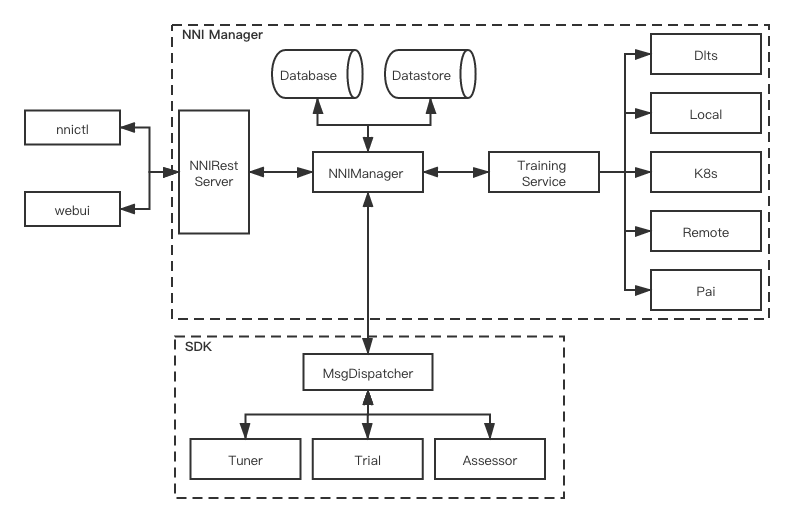
基本架构
![]()
NNIManager是管理中枢,负责管理串联Trial、Rest接口服务、中间数据存储、日志调用服务、配置文件服务、训练平台服务等。 SDK是一系列核心类的实现,包括MsgDispatcher、通信协议、Tuner、Trial、Assessor等,其中MsgDispatcher是整个消息处理的中心。
基本流程
NNI运转流程可用以下伪码描述:
输入: 参数搜索空间、Trial类实现、配置文件
输出: 最优模型参数
算法:
\[ \begin{align*} & 1: For \ t = 0, ..., trial个数:\\ & 2: \qquad 超参数 = 从搜索空间选择一组参数\\ & 3: \qquad 最终结果= 用上步给定超参数训练trial并做效果评估\\ & 4: \qquad 将执行结果反馈给nni\\ & 5: \qquad 如果到达最大迭代次数或满足提前停止迭代条件:\\ & 6: \qquad\qquad 结束实验\\ & 7: 返回最优超参数和相应模型权重 \end{align*} \]
执行效果
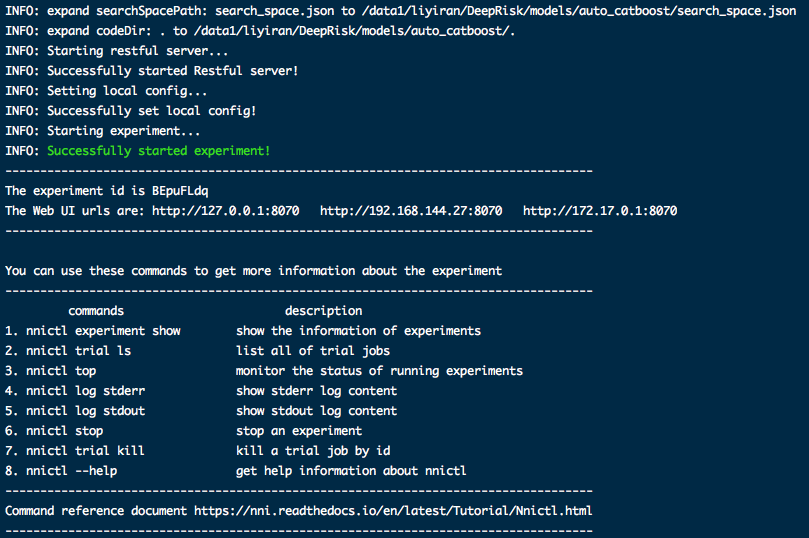
1、控制台上会显示一次实验的概览以及webUI地址:1
2nnictl stop
nnictl create --config models/auto_catboost/config.yml -p 8070![]()
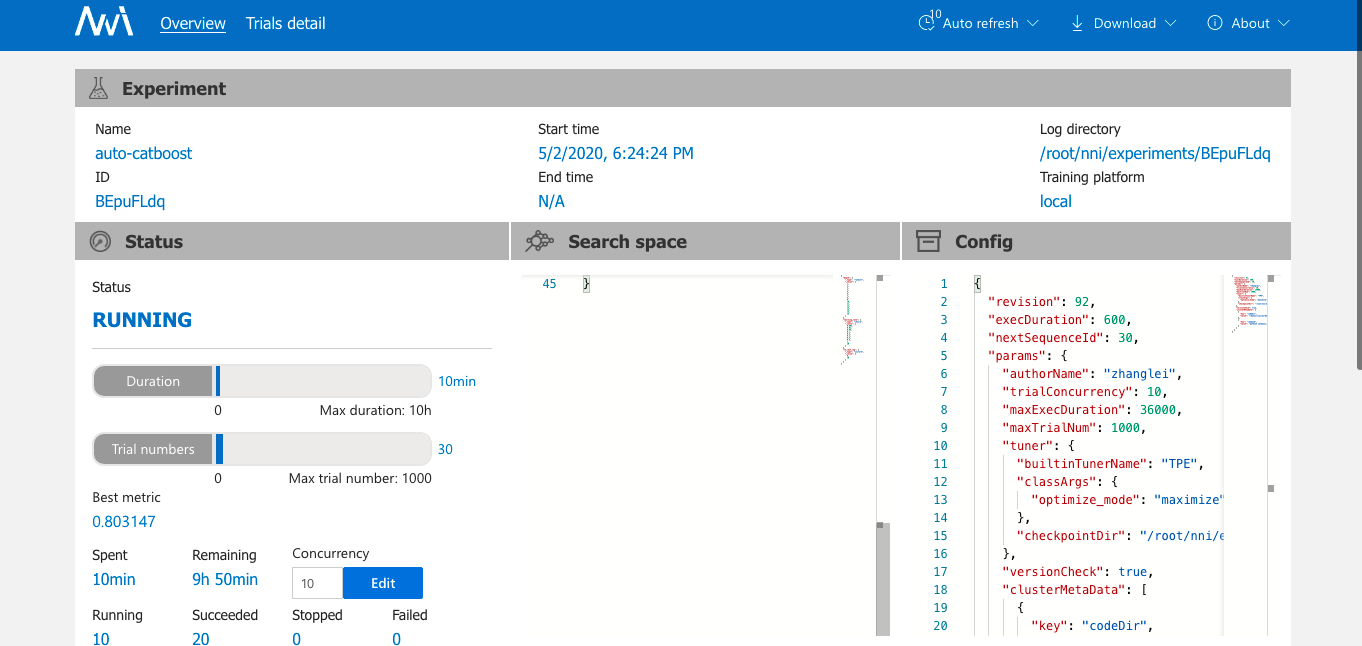
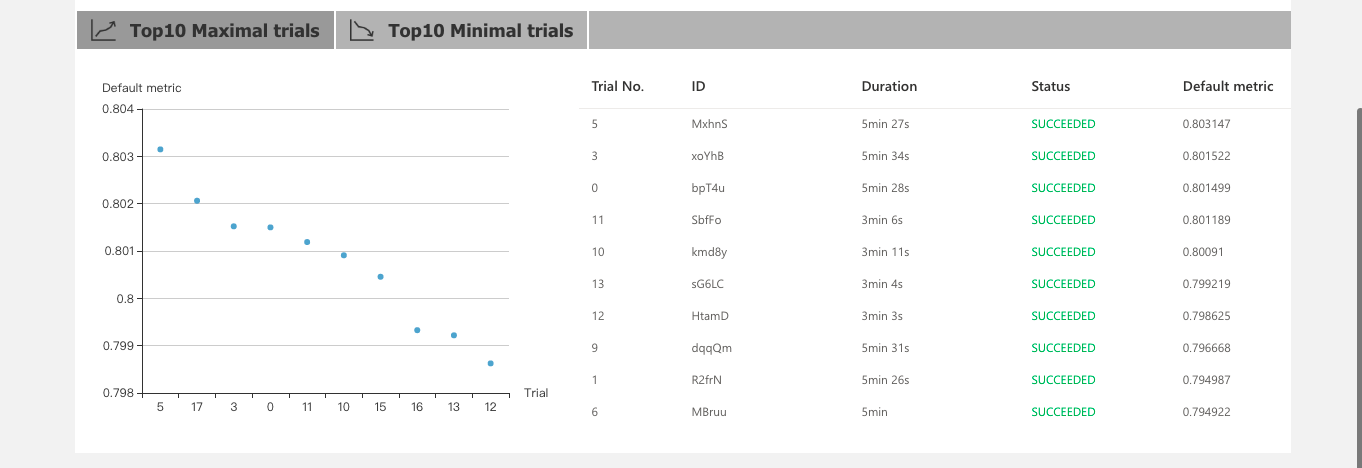
2、首页展示实验当前状态,包括参数、运行时长、当前最优模型、效果最好的Top 10 Trial情况。
![]()
![]()
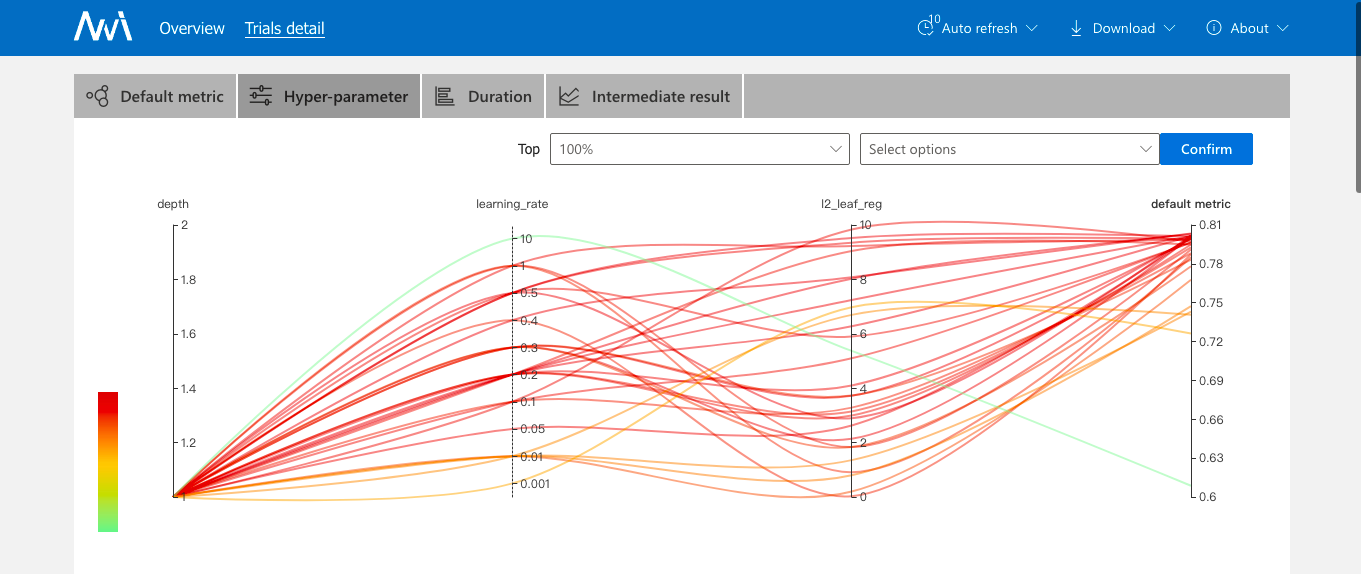
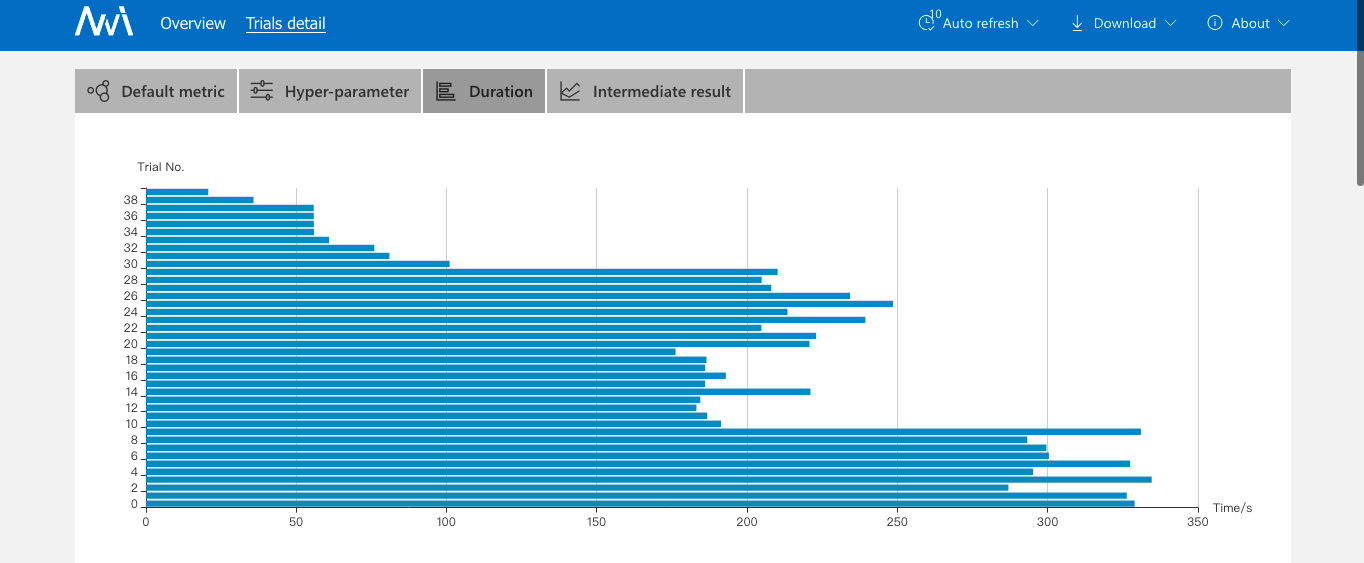
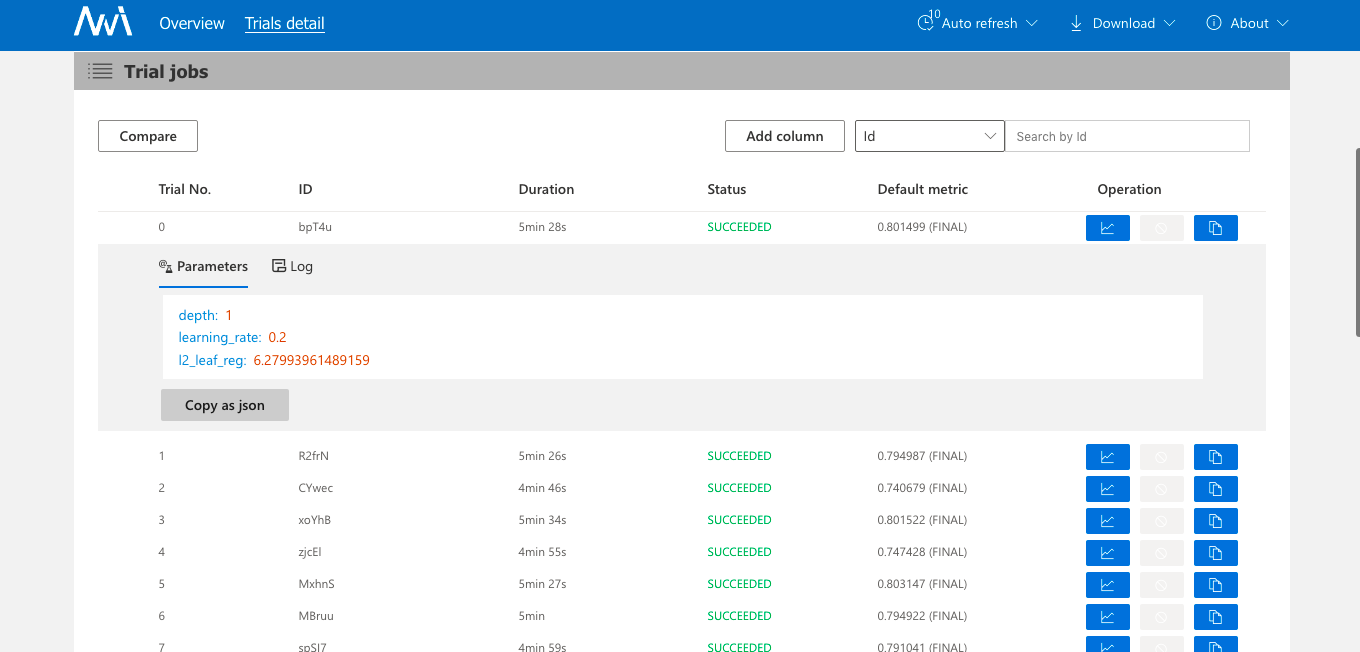
3、详情页会展示超参数搜索情况、每个Trial执行时间和它的执行日志、参数情况,这里有个缺点是查看日志不方便,需要拷贝日志路径到宿主机上看,另外调试也不太方便。
![]()
![]()
![]()
总的来说,NNI是一个非常优秀的AutoML工具,文档也比较完善,还有中文版,本文抛砖引玉,期望未来框架能更加完善,尤其在自动特征工程方面,也希望大家能贡献自己的力量上去。