 分享对AI及LLMs的一些认知。
分享对AI及LLMs的一些认知。
迎接AI的下一个时代
AGI正在到来
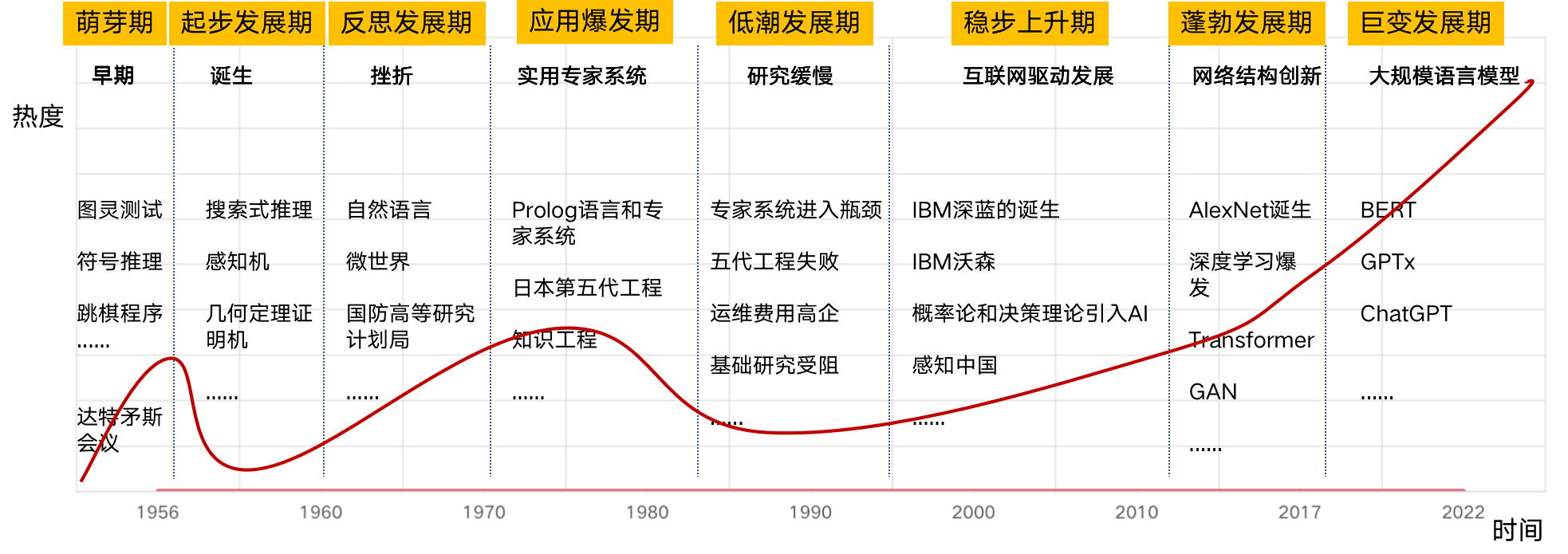
AI发展史
AGI应该具备的能力: - 具备人类的“认知”能力,具有“理解”能力 - 执行人类能完成的任何任务 - 面对从没有见过的问题能够推理或演绎地给出解决方案 - 具备快速学习和小样本学习能力,可以学习“常识”
现阶段的AGI概括起来由以下几个部分组成,我认为是一个中间过程: $ AGI_{now} = + + $ 其中: - DL:以神经网络为基础,通过训练大量样本数据来学习数据特征,以反向传播方式迭代更新AI系统的权重,尤其是非监督或自监督的方式,可以认为是把“知识”及其“上下文”压缩在某个隐语义空间中 - RL:我们面对的实际问题往往没有标准答案,所以合理的方式之一是通过与动态环境的相互作用来迭代效果,在强化学习中,AI系统会根据当前环境发出的反馈信号(也叫奖励或惩罚),调整自己的行为“策略”以在未来获得更高的“回报” - IL:在模仿学习中,模仿的对象通常是人类专家,例如:在ChatGPT训练的最后一步,AI系统通过观察人类专家在不同情况下的行为,学习并建立相应的策略来模仿这些行为”
ChatGPT的影响

我认为概括起来是以下几个方面: - 措手不及:ChatGPT的横空出世,让所有公司都措手不及,没想到这一天会这么快到来 - 全行业焦虑:全行业在一开始都处于焦虑状态,对一项颠覆式的创新到底对大家会有什么影响有很多不确定性,尤其是以NLP技术为主的相关公司 - 不可逆转:跨越式技术创新一旦实现,其趋势不可逆转 - 迎头赶上:大型公司需要迎头赶上,否则落后一步则步步落后,中小公司要用好大模型,做产品和垂直领域创新,走差异化路线 - 垄断效应:不管是从人力、算力还是高质量数据方面,真正的基座大模型(三天两头有号称自己搞了大模型的公司,要么是PR稿,要么是基于开源大模型如LLaMA做了下小数据集训练)一定会被头部企业垄断 - 抢生态时间:最终大模型不会以一个孤立点存在,一定是一种生态,例如:windows/Linux生态、苹果生态,所以谁能抢占到谁将获得先机,OpenAI的生态已经有雏形了
认知割裂还是暗渡陈仓?

学术界在是否控制大模型方面产生了认知撕裂,相信这种状态会长期延续下去,例如,最近在是否停止训练GPT-5(虽然官方说没有GPT-5)上产生了巨大分歧,我自己的认知倾向于,目前的AI是通往AGI道路上的一个过程。
我国的态度
从学术界和工业界来看,大家由于处于落后者,所以一定是奋起直追,缩小差距,尤其以朱松纯教授为代表,认为国家对AGI应该以“两弹一星”的精神去搞,从民间来看,中国人民对AI这种新事物的接受度也最高,我认为这是我国全民教育体系产生的良好效果(毕竟西方人民很多不知道月球围绕着什么转,但是知道5G会传播新冠,呵呵),当然在国内应用大语言模型,一定要满足国家监管要求,所以网信办很快的出了《生成式人工智能服务管理办法(征求意见稿)》,这也是国内巨头还有机会的原因之一。

https://www.chinatalk.media/p/ai-proposals-at-two-sessions-agi
https://mp.weixin.qq.com/s/2-qP6qc_8NigbP7djv2k0w
现象级产品介绍
Auto-GPT

AgentGPT
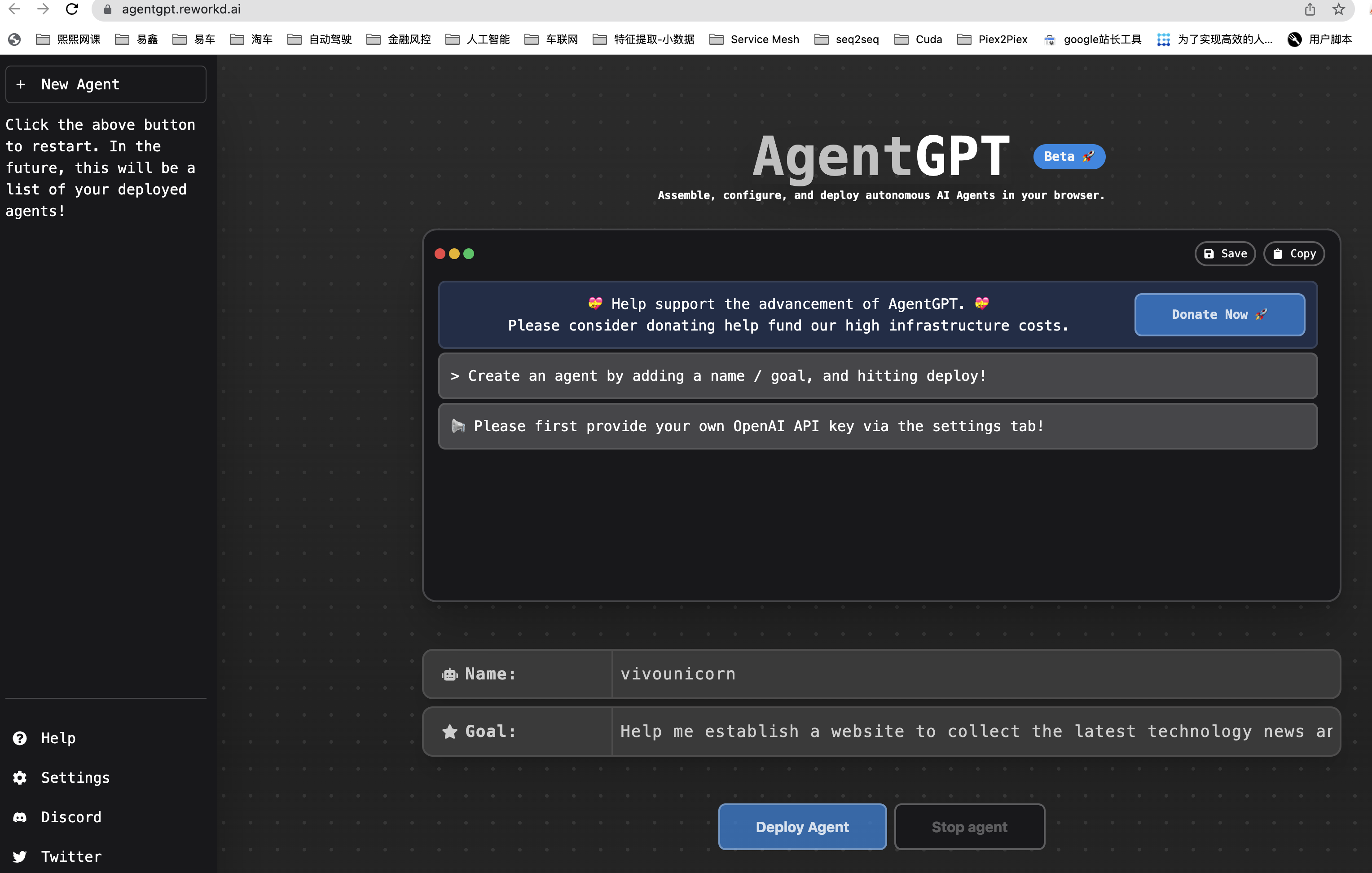
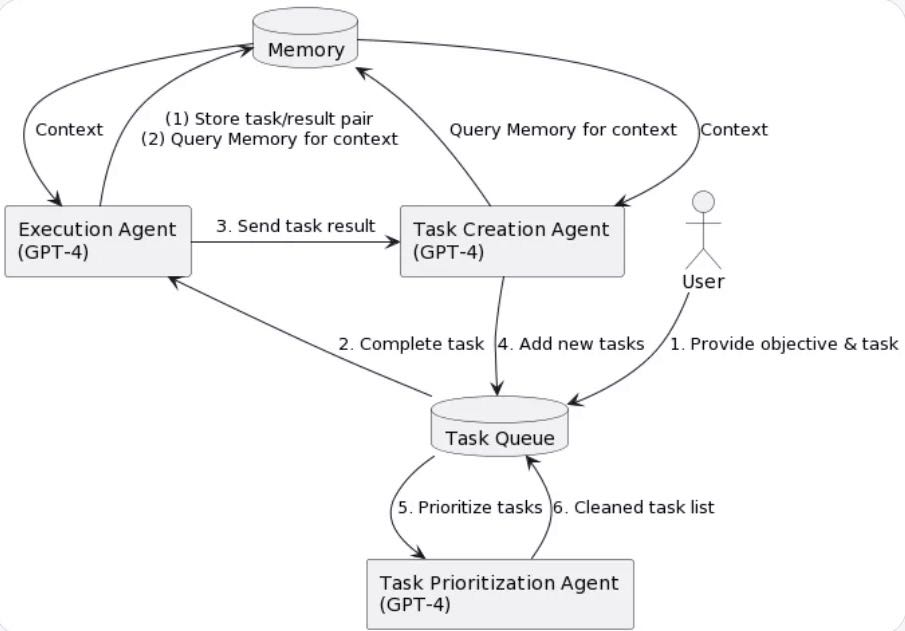
虽然现在还是试验性产品,但未来Prompt也逐渐变成自动化的,人们只需告诉AI系统目标是什么,剩下的就只需要在旁边看了,当然,实践时,毕竟GPT-4的价格是GPT-3.5的十几倍,所以要求更高的agent用它,像总结这种没那么高要求的用更便宜的3.5,高低搭配(ps:虽然3.5在这里是打辅助的,但出了open ai它是大部分公司的天花板,这就是差距)。
MidJourney
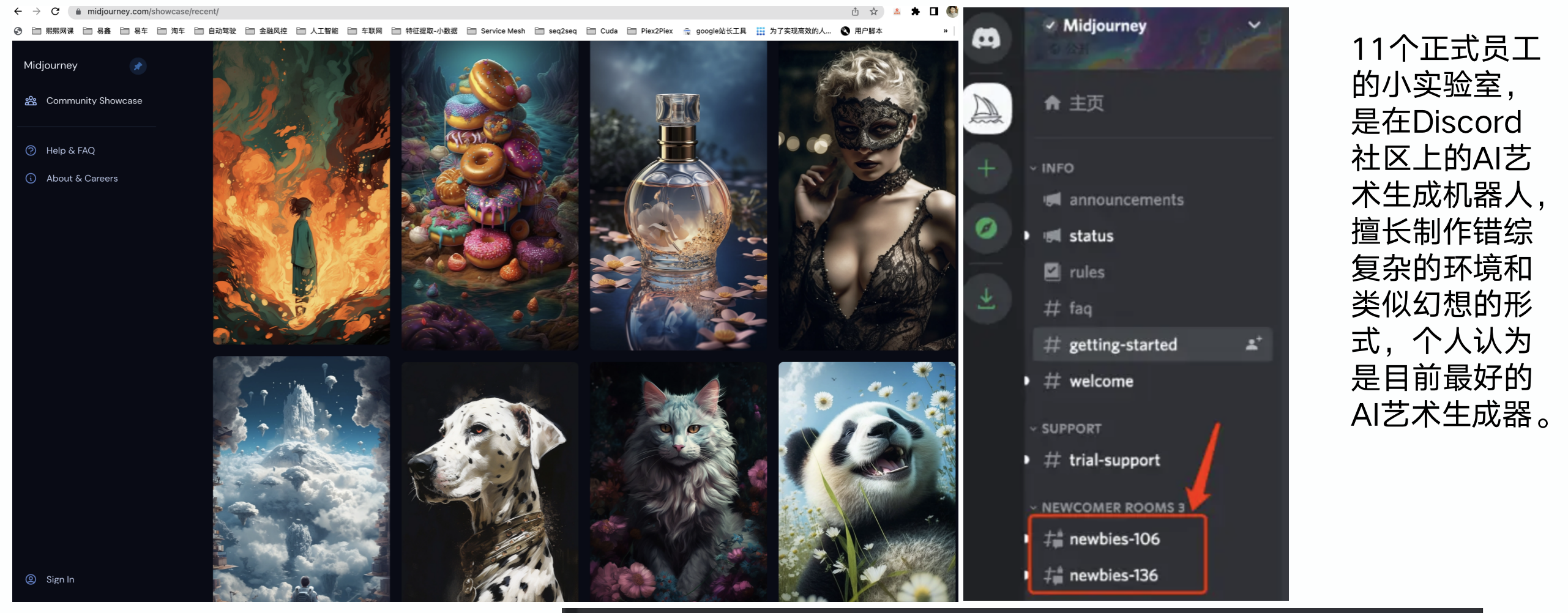
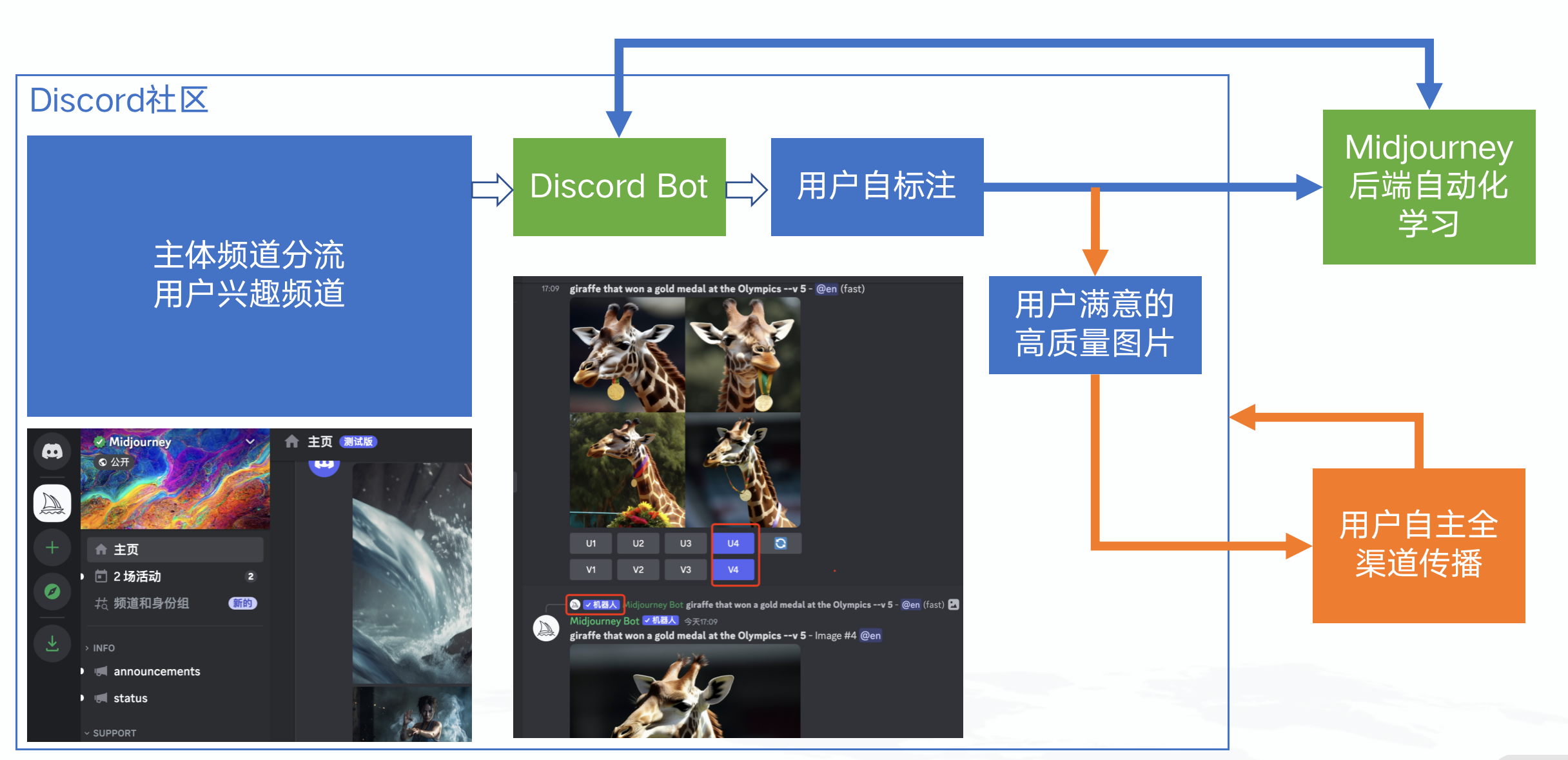
基于Discord社区,只有绿色部分是需要MidJourney自己开发的,这里非常牛的产品设计是:每次让用户自己选择哪张图更好,让用户成为标注员,从生产、标注到传播成了一个闭环,整个模型迭代将以前所未有的速度进行。
关键技术和概念
开源模型
开源大模型如雨后春笋板出现,直叫人跟都跟不过来,例如: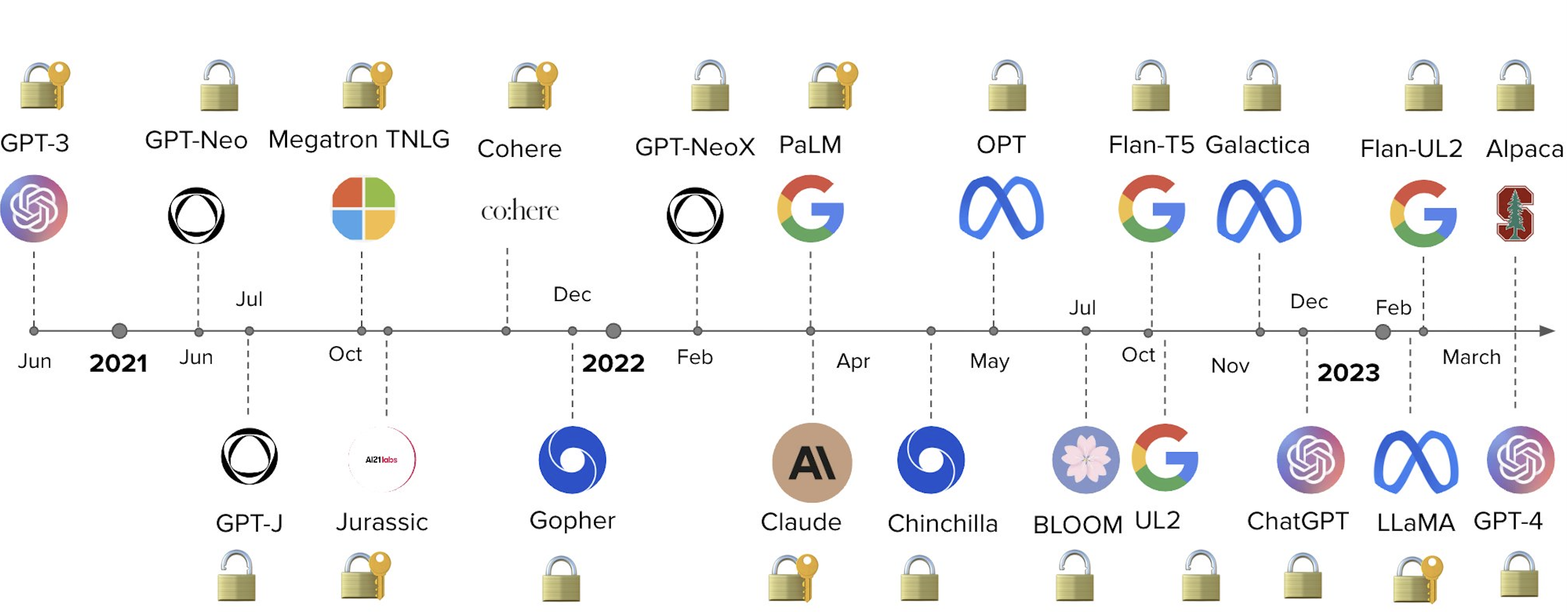
以及:
- PaLM-rlhf-pytorch
- Stanford-Alpaca
- Point-Alpaca
- Talpaca-lora
- LLaMA
- Llama.cpp
- Llama-es
- Chatllama
- Lit-llama
- Gpt4all
- ColossalA
- FastChat
- ChatRWKV
- Xmtf
- Trlx
- Dolly
- BELLE
- minChatGPT
- Cerebras-GPT
- TavernAI
- GPT-J 6B
- Vicuna
- OpenChatKit
- ChatGLM-6B
- MOSS
- ......
但是在中文场景下,能打的几乎没有,只有ChatGLM-6B勉强还可以,越是这样大家越应该努力并不要浮躁,别拿开源模型随便搞了搞就说是自己的大模型,然后各种PR稿,太丢人了。
基本概念
其实本站讲了很多基本概念,感兴趣的可以回看,我只抽些重点: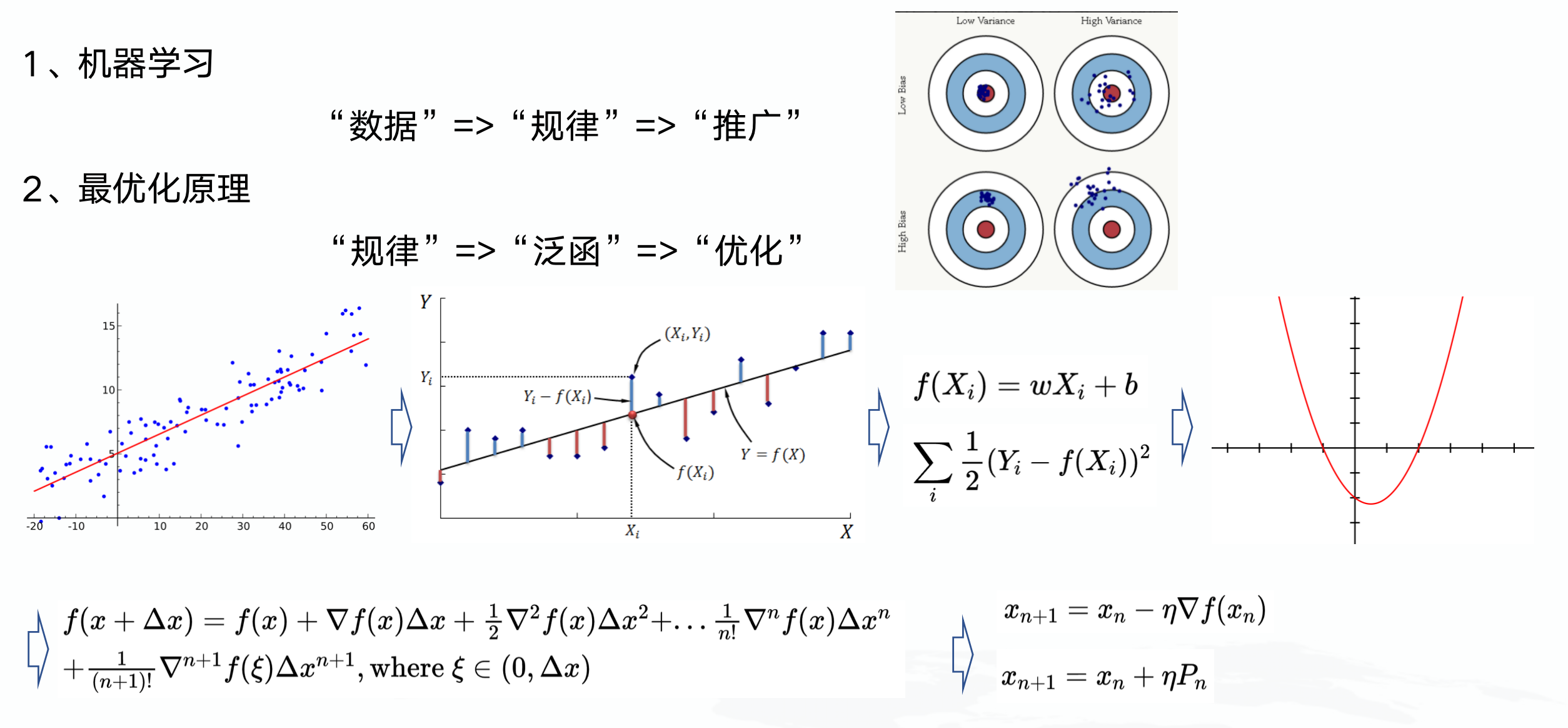
大模型的本质依然是机器学习,至于其“涌现”能力为什么会出现,目前我还没看到完备的数学理论(也许就是没有,无法解释)。
Attention机制与Transformer是大模型的根: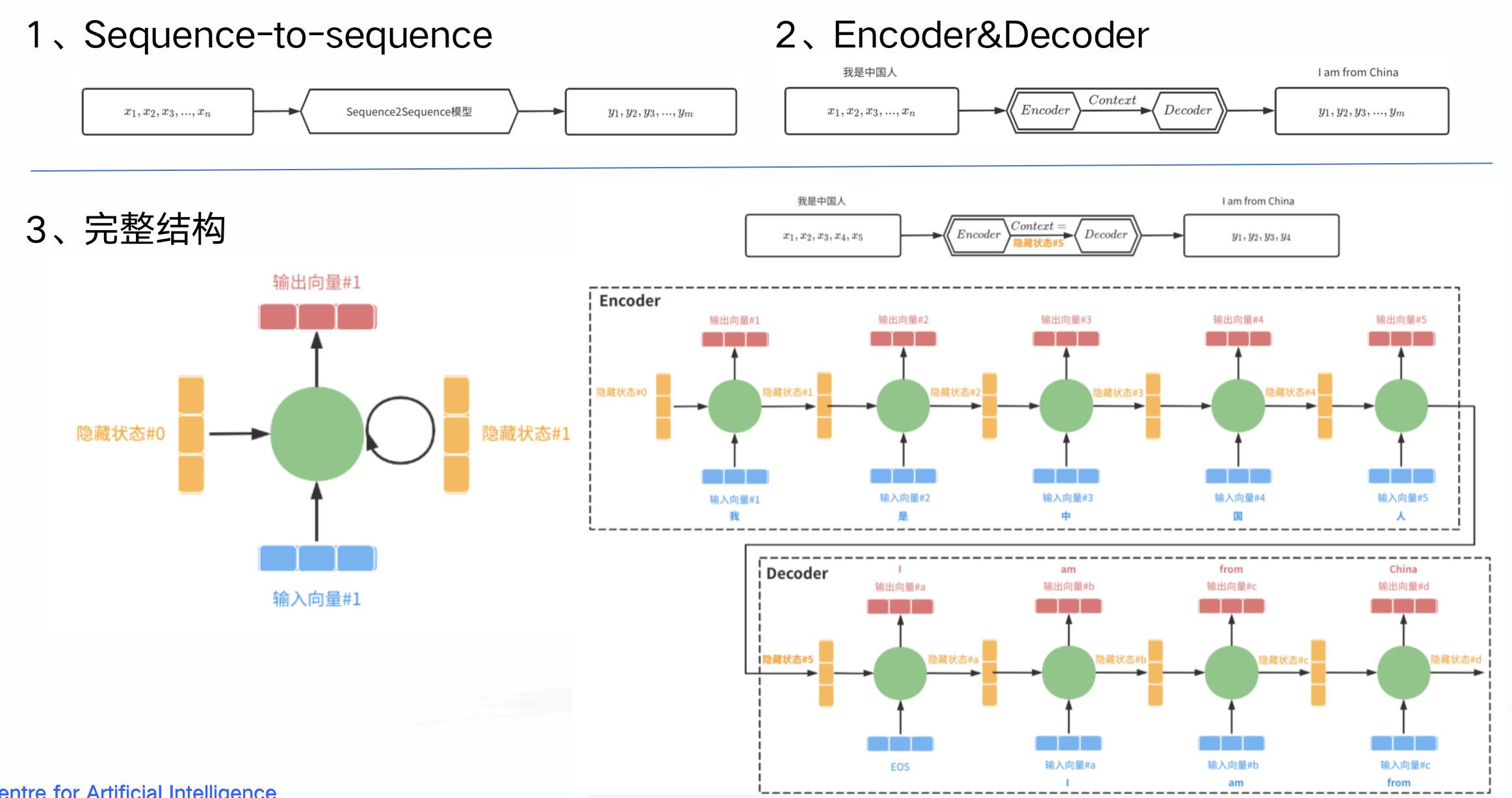
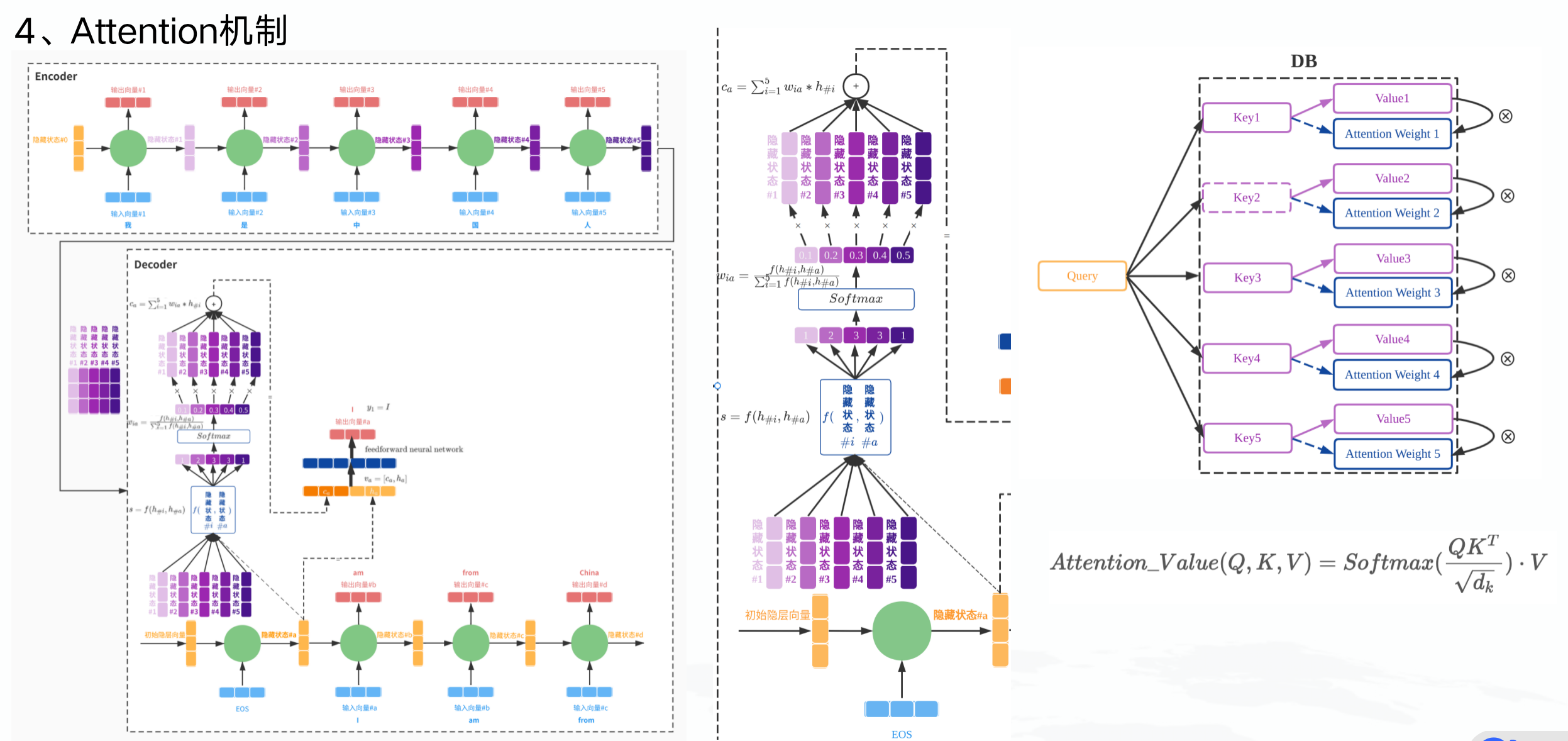
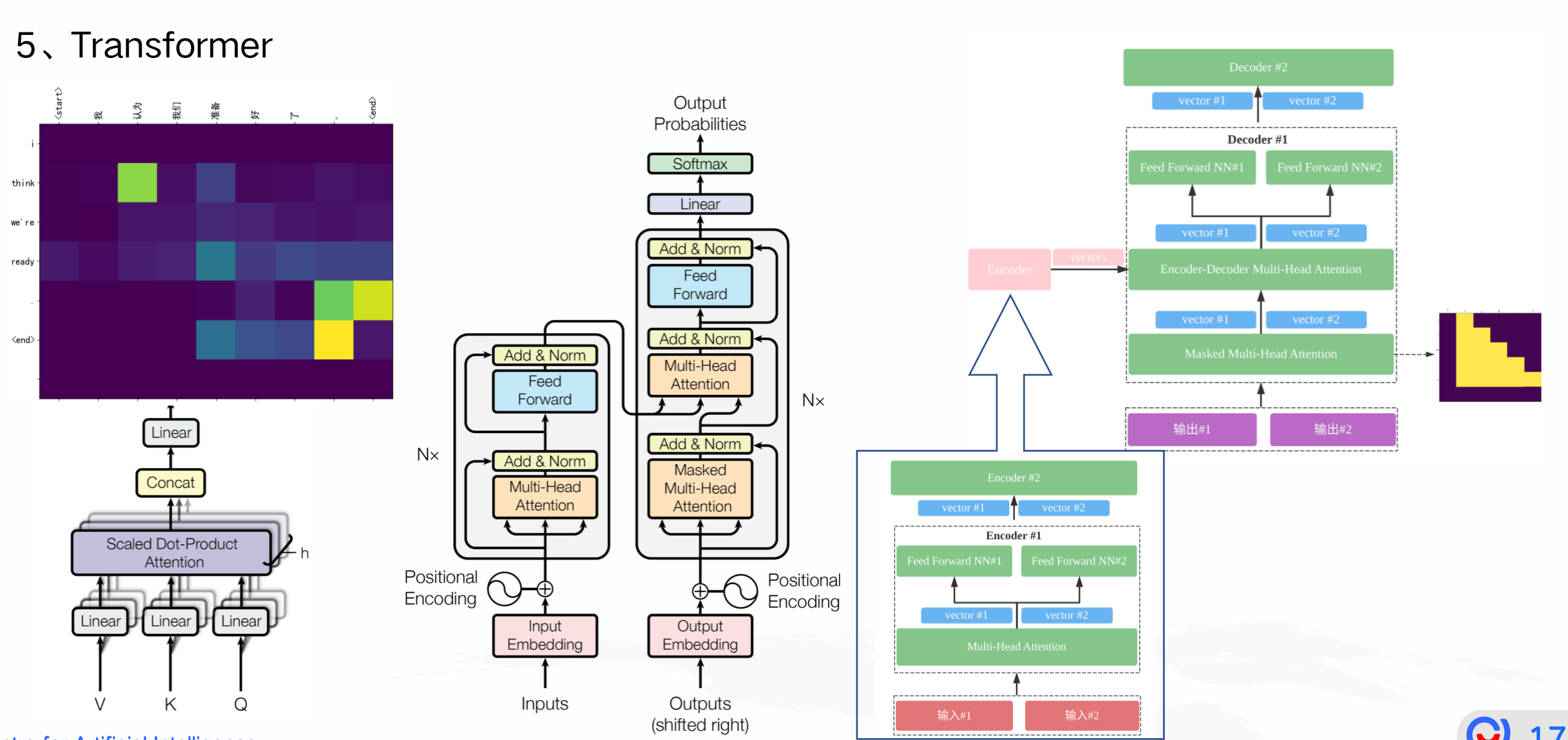
Fine-Tuning
本质上是站在巨人的肩上,LLMs负责学到“通用语义表示”,以预训练模型(PTMs)的形式提供给下游任务,下游利用fine-tuning技术负责具体问题具体分析。
学习范式也发生了改变: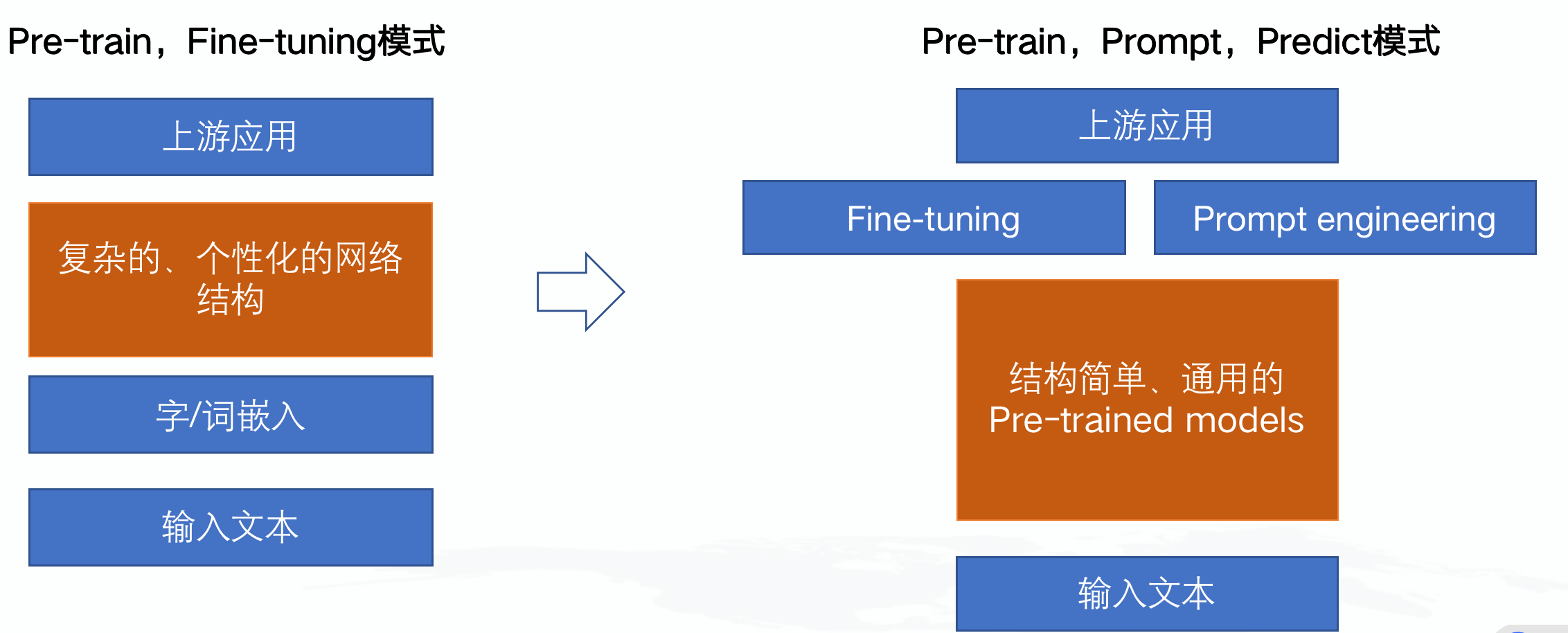
语言的Distributed Representation
文本需要通过某种方法以数据的方式表示出来,这样才能让机器去处理,可以是字、词、句子粒度。
1、以One-hot为例的简单方法
2、Distributional Representation:从概率分布的假设出发,若两词的上下文相似,则这两个词语义是相关的

3、Distributed Representation:无概率分布的假设,直接将文本的语义分散在一个低维空间中

语言表示模型可以看作: 1、用某种方式对文字做了数字化抽象和表示,可以是基于神经网络,也可以是矩阵分解 2、对文字中蕴含的潜在语义信息做了低维压缩,以向量形式在某个Latent Space呈现
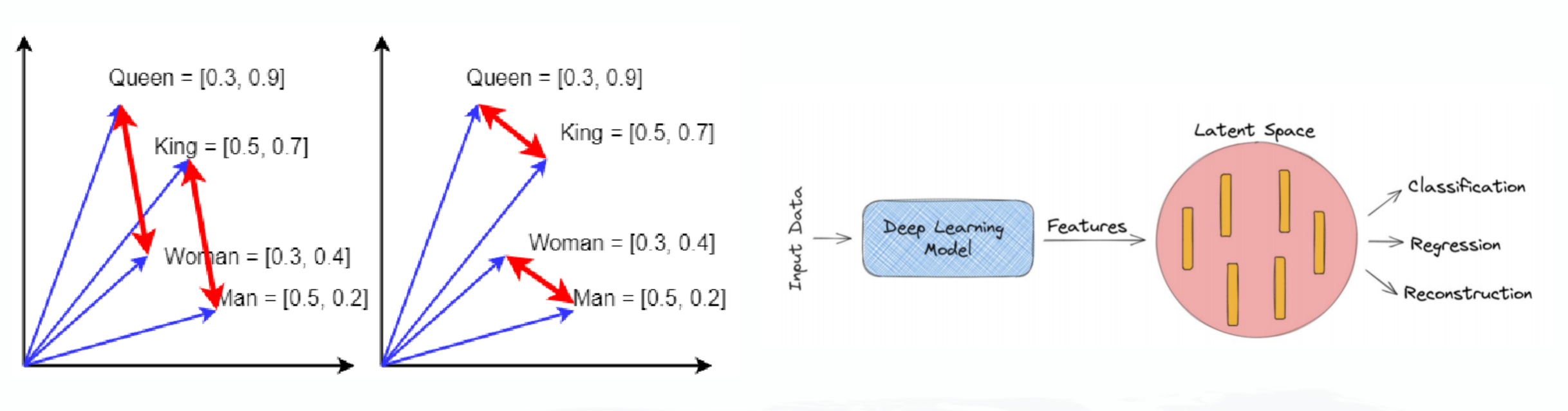
预训练模型的阶段
第一代PTMs: 目标是学习到好的word distributed representation,也叫word embeddings,会以低维词向量形式出现(如一个250维的向量),然后模型本身参数被丢弃了,典型的例子是word2vec(Skip-gram或CBOW模式),但它们只能捕捉到词的“低级部分”语义信息,与上下文关联也不大,“高级部分”尤其是高级抽象和概念无法被捕获,例如:词性标注、NER、句法分析、指代消解。
第二代PTMs: 以基于Transformer结构的GPTx/BERT为划时代的代表,集中在同时学习“低级”和“高级”语义信息上,可以捕捉到文本数据中隐含的语法规则,保留了模型本身,并直接在下游任务应用。同时,过去的很多中间任务也消亡了,例如:分词、词性标注、NER、句法分析、指代消解等等,因为大模型已经把这种“高级”信息“吸收”进了Transformer结构的参数里了。
NLP任务庞大而复杂,且结构化弱,本身的数据规模又特别大,但缺少大规模人工标注的数据集,而没有好的标注数据集,NLP任务结果往往不可用。
给定一个文本序列:\(x_{1..T}=[x_1,x_2,x_3,...,x_T]\),其联合概率分布为:\(p(x_{1..T})=\prod\limits_{i=1}^{T}p(x_t|x_{0..t-1})\) 进而对每个token,拆解条件概率:
\[ p(x_t|x_{0..t-1})=g_{LM}(f_{encoder}(x_t|x_{0..t-1})) \]
LLMs的出现,把NLP任务分成两段论,与CV领域类似,使得:
- 基于大规模文本数据的自回归PTMs可以很好的学到通用的语义表示,有助于下游任务应用
- 提供了更好的神经网络初始化参数,从而让模型具有更强的泛化能力,让下游任务收敛速度更快
- 被视做一种正则化方法,控制模型方差(Variance),有效预防在小规模标注数据上的过拟合
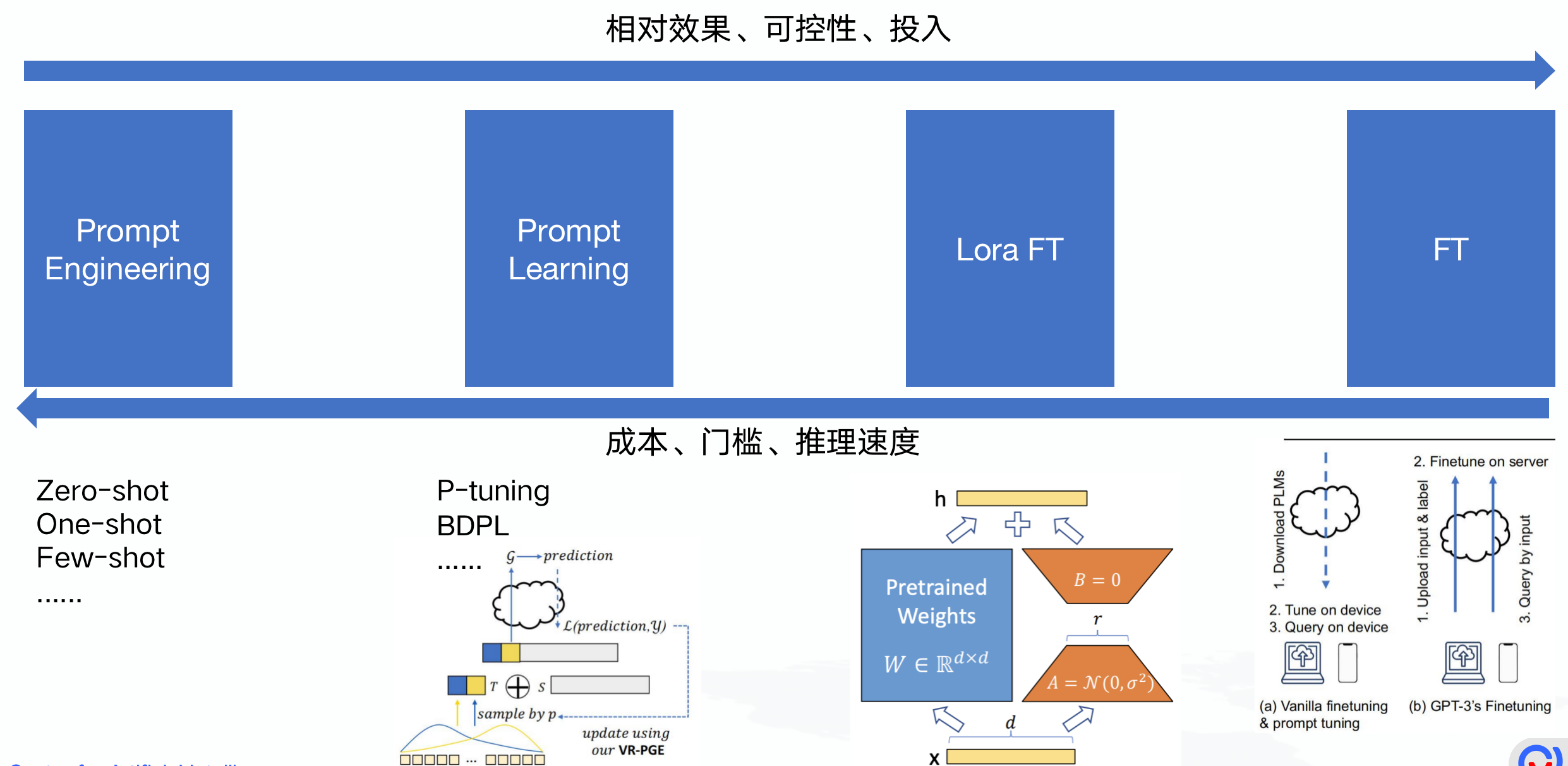
预训练模型传统用法
Pre-train,Fine-tuning模式有什么问题? 1、PTMs模型越大,微调模型时需要的计算资源越多 2、PTMs对不同下游任务需要做模型微调,需要“被动适应”各种下游任务,通过引入各种辅助任务的损失函数实现,整个过程中PTMs做出了更多的牺牲 3、需要为每个下游任务复制整个PTMs的副本,且在线Inference必须在单独的batch中执行
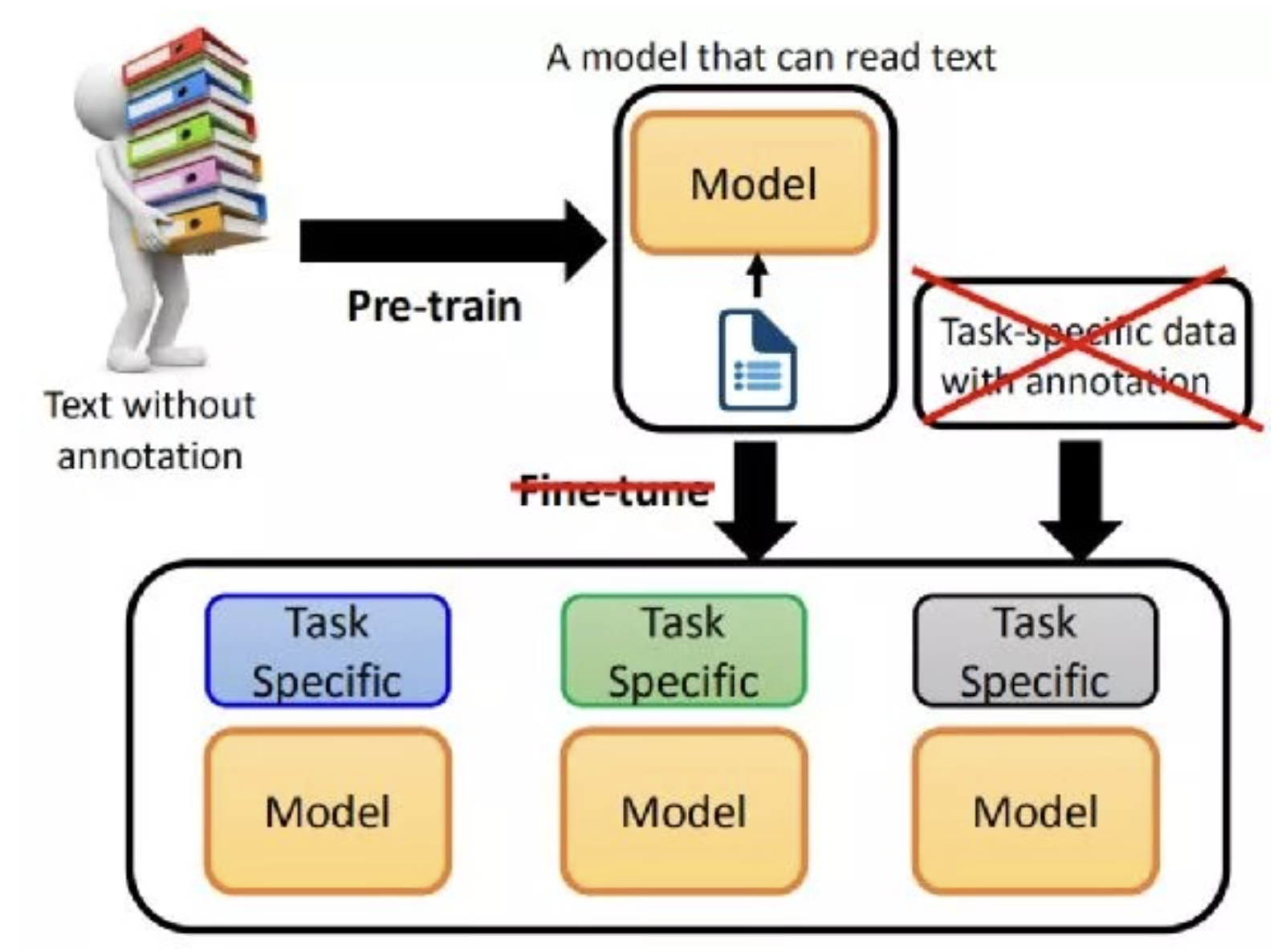
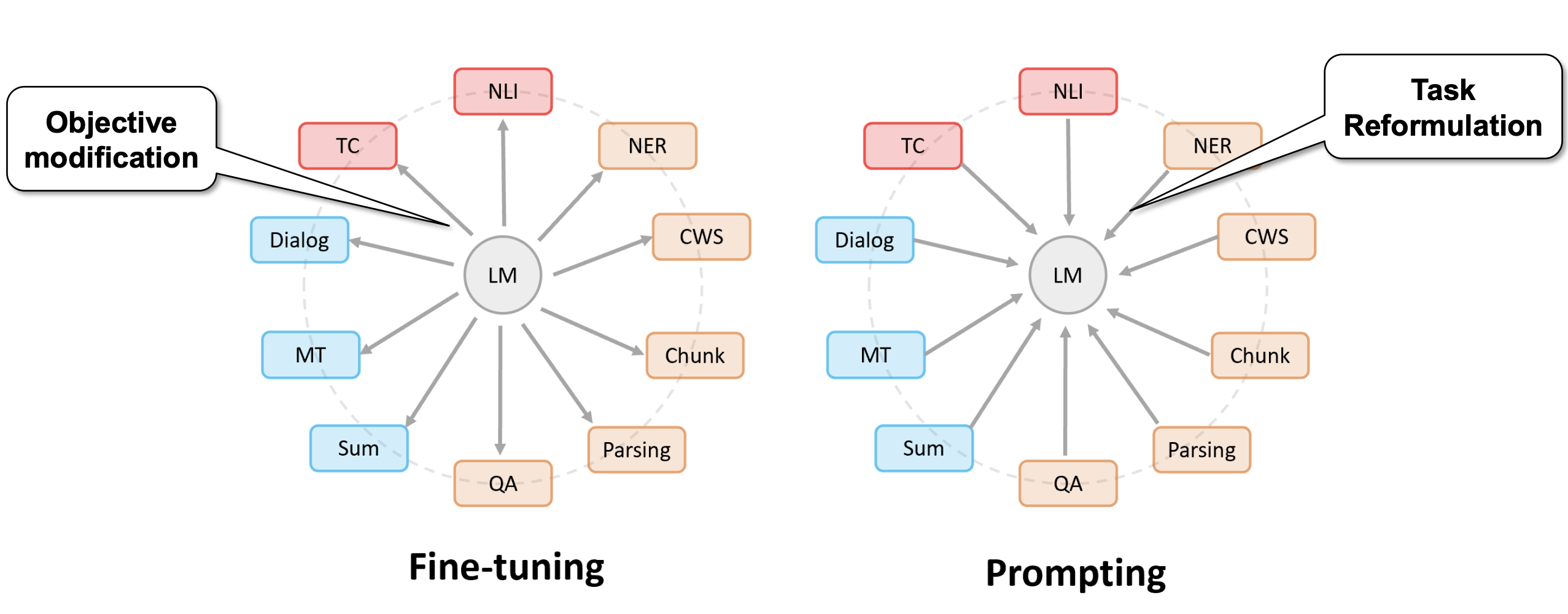
预训练模型新用法
Pre-train,Prompt,Predict模式 1、无需fine-tuning,参数量少,所以需要的计算资源少 2、PTMs直接适应下游任务,简单直接 3、下游多任务共用整个PTMs的副本,且在线Inference执行效率极高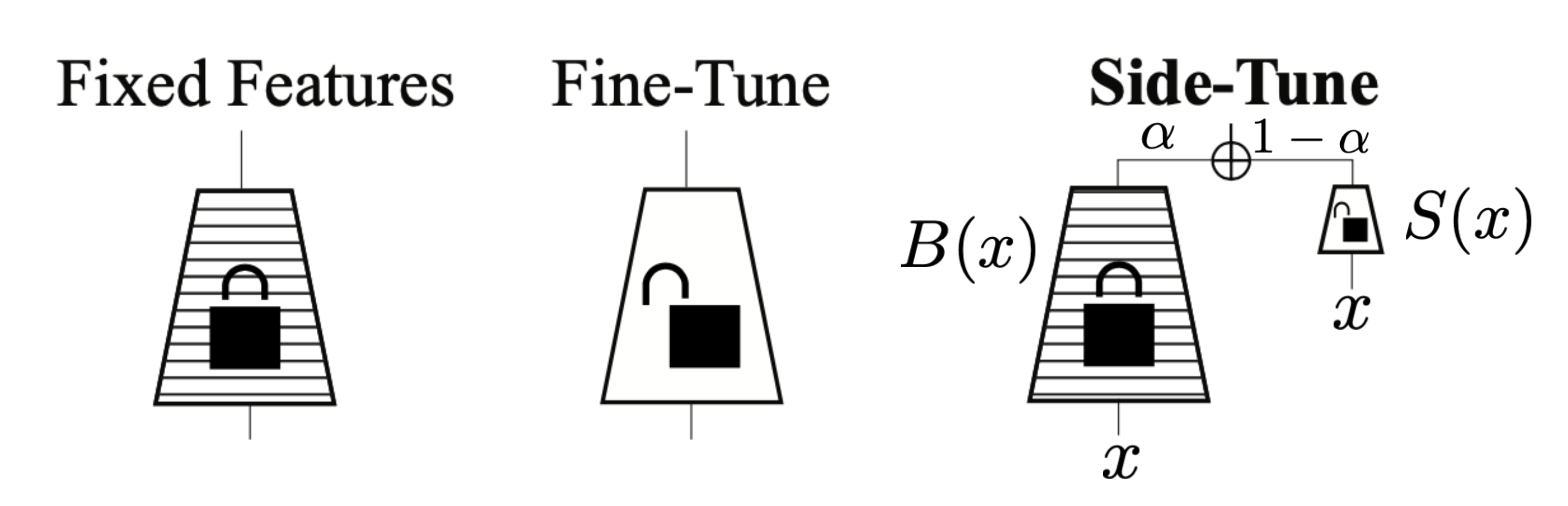
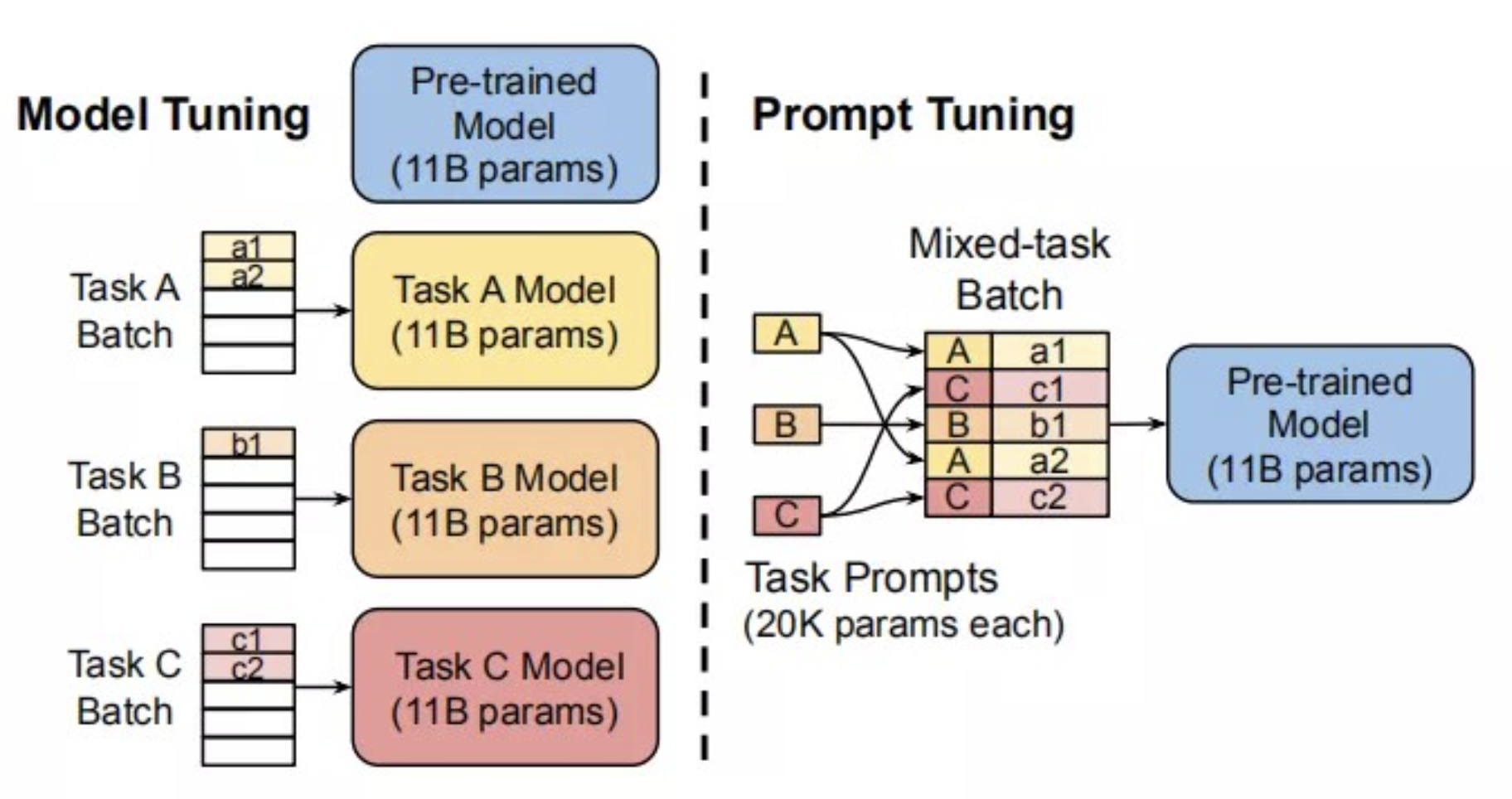
文生文&文生图
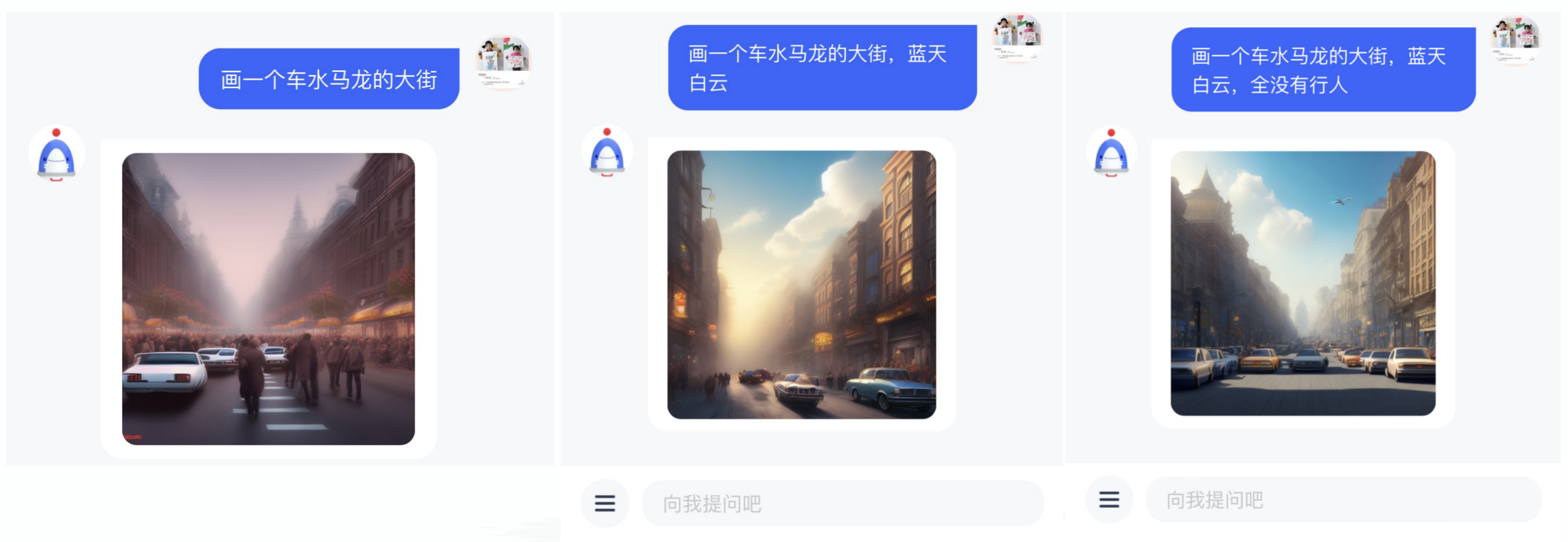
Prompt 1:


Prompt 学习的三种范式
Zero-shot
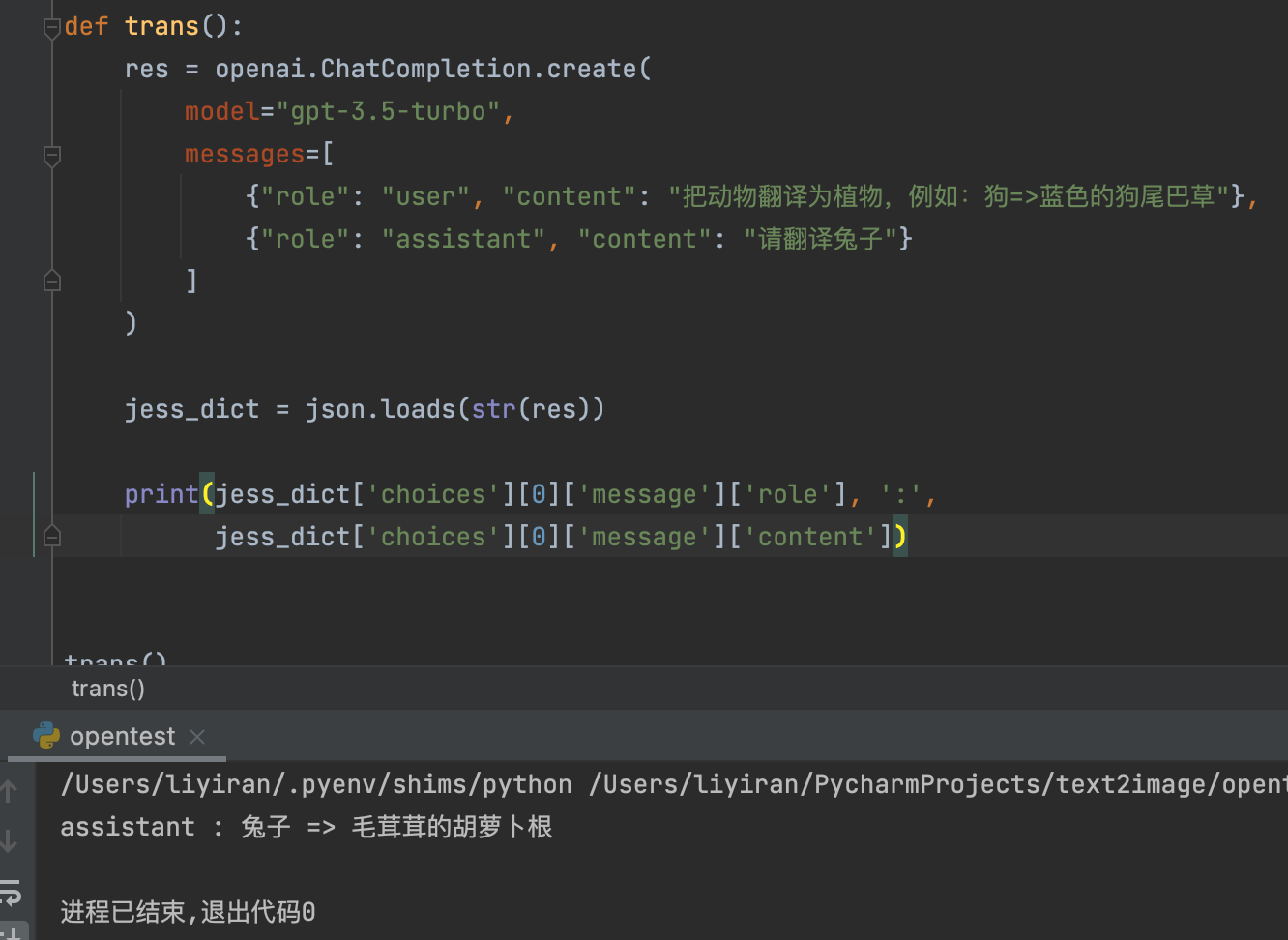
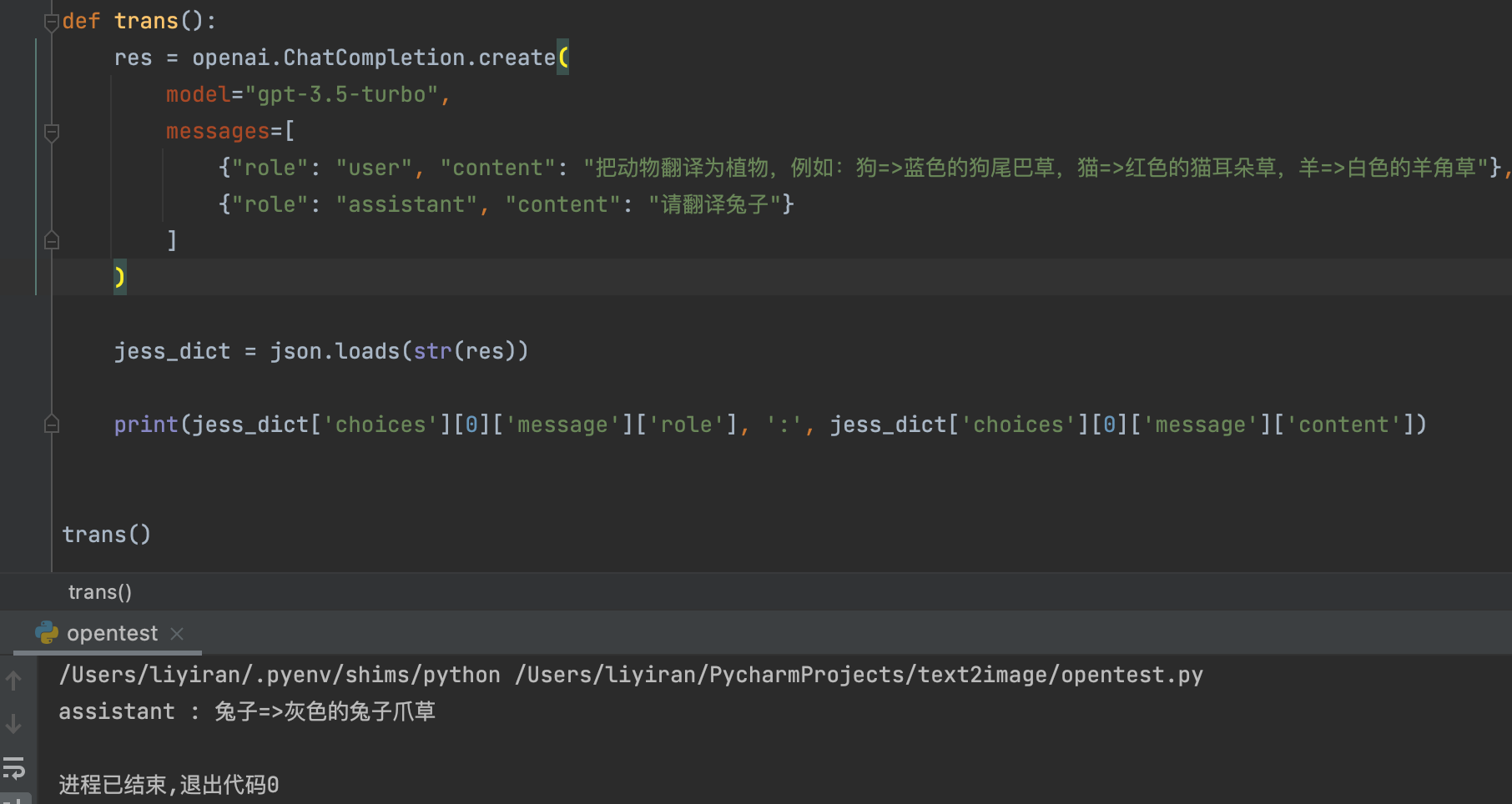
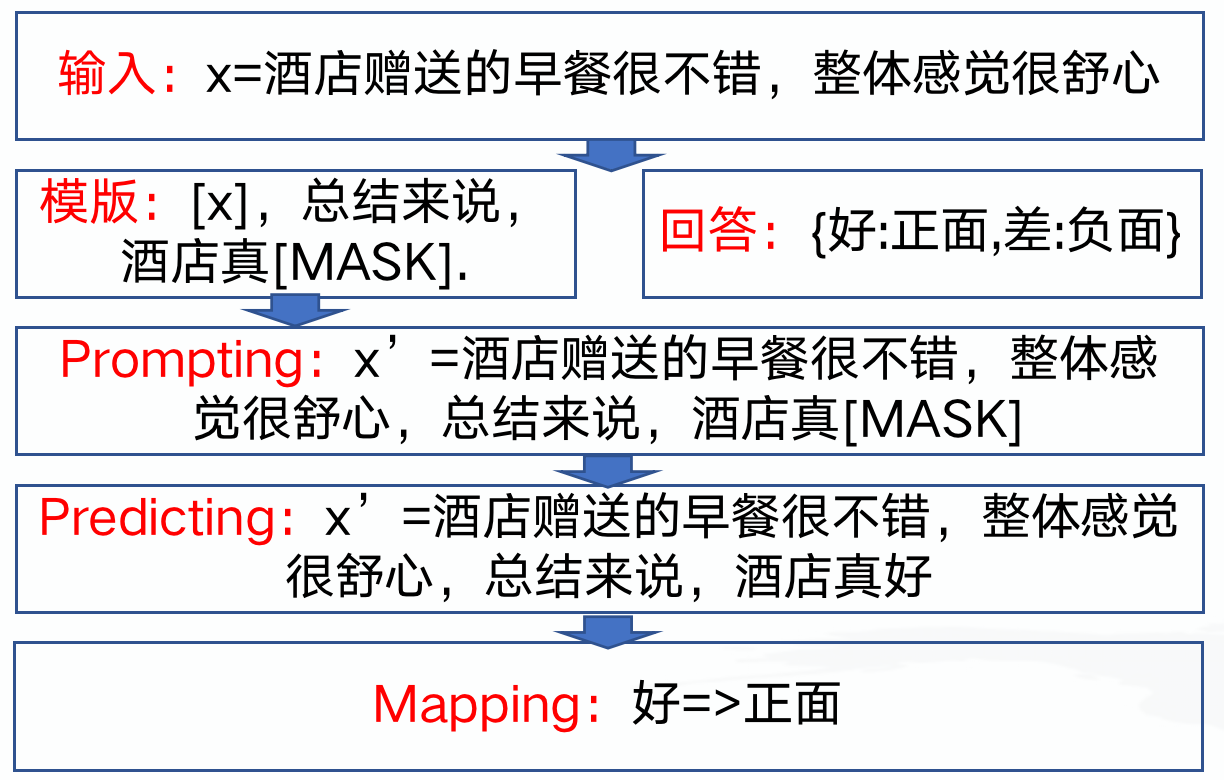
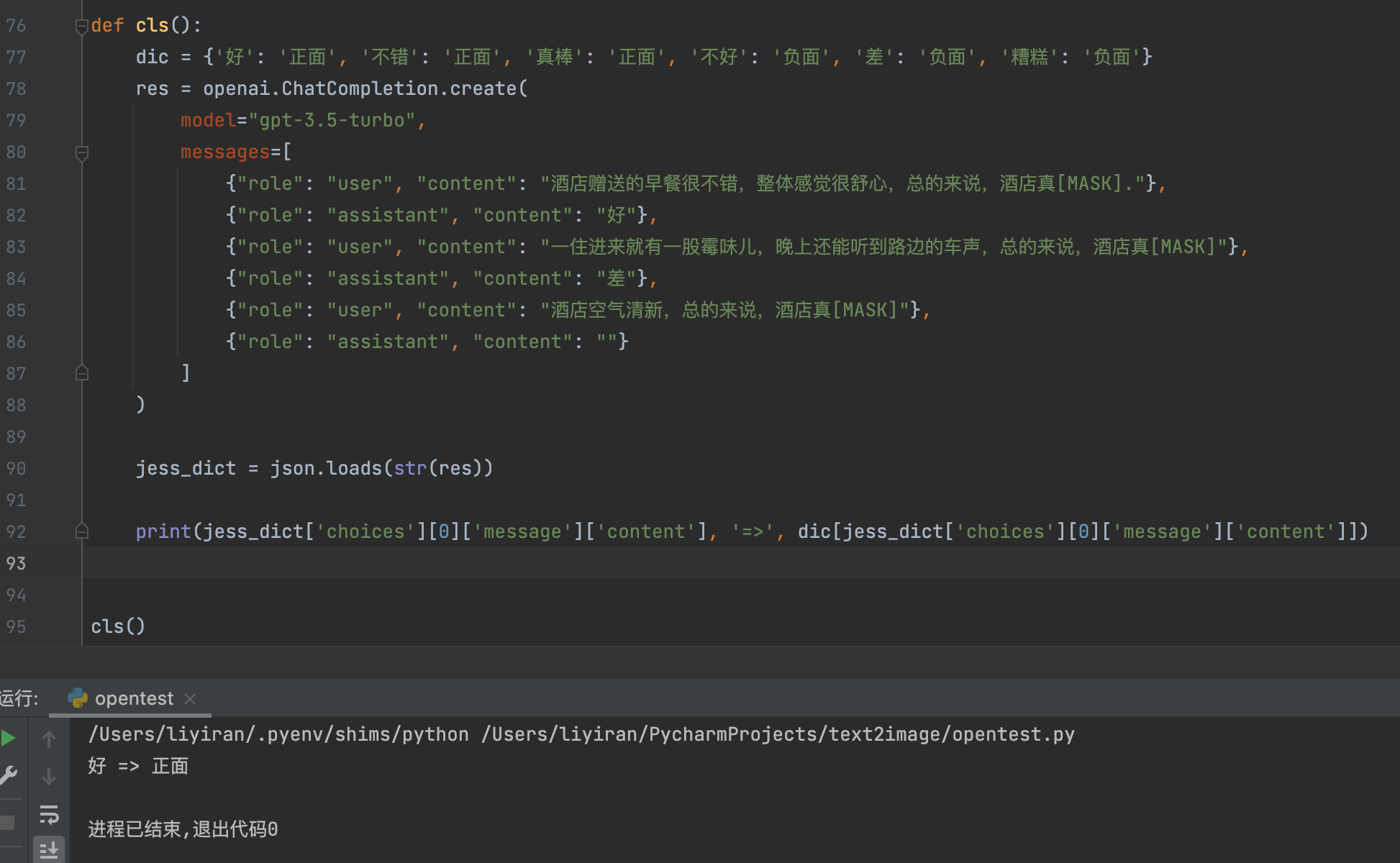
管中窥豹 让所有NLP任务都看作语言建模问题 以情感分类为例: 1)、定义模版“唤醒”LLMs的“记忆” 2)、把LLMs的输出结果映射到情感标签

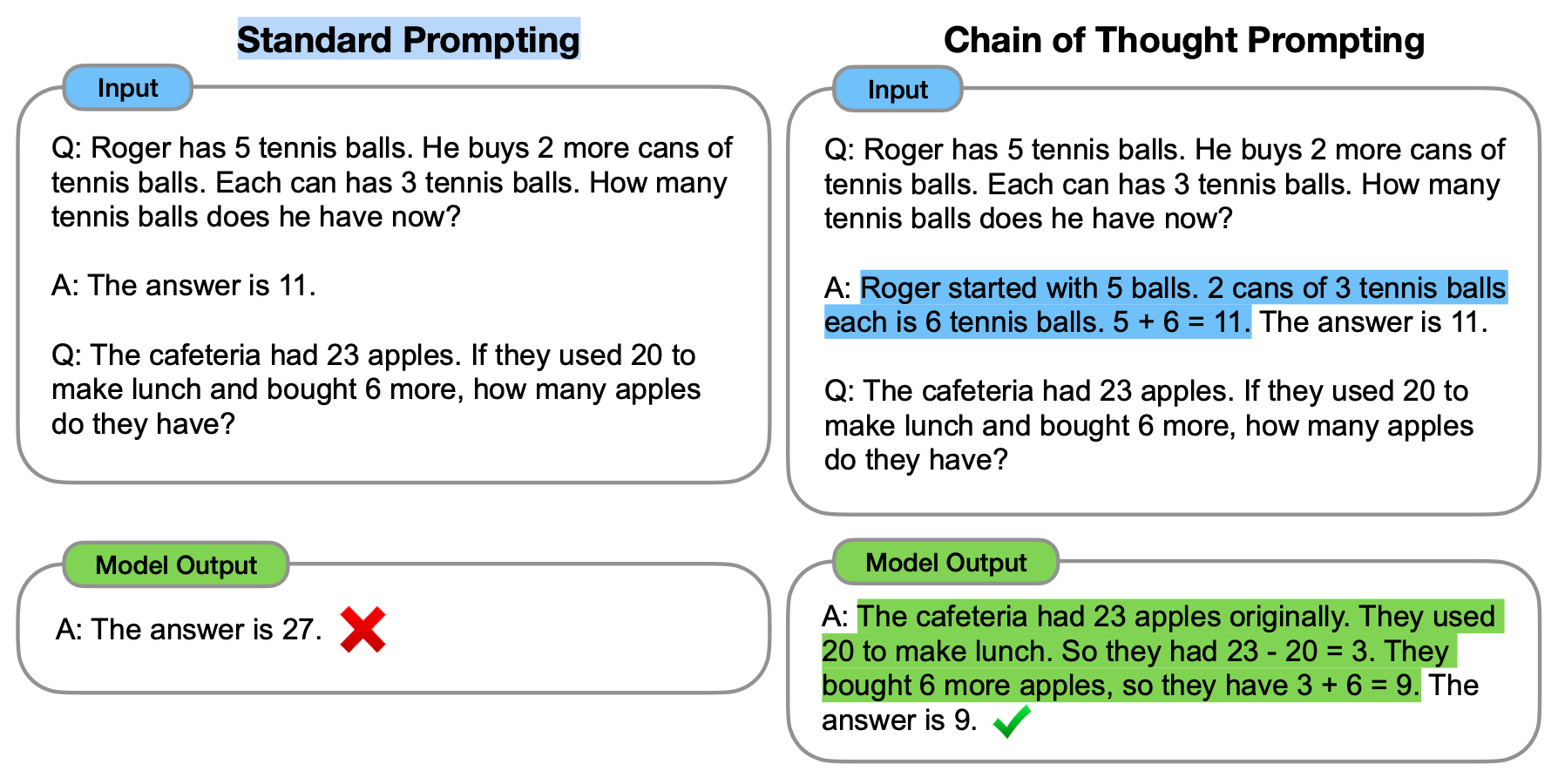
Chain of thought
Cot就是通过少量例子“提示”模型如何逐步完成推理任务,prompt的输入为三元组<input, cot, output>,其中cot是为了得到最终结果的一系列中间步骤,cot一方面能提高模型输出的准确度,另一方面也能把大问题拆分,在Auto-GPT上也可以看到其很好的应用。
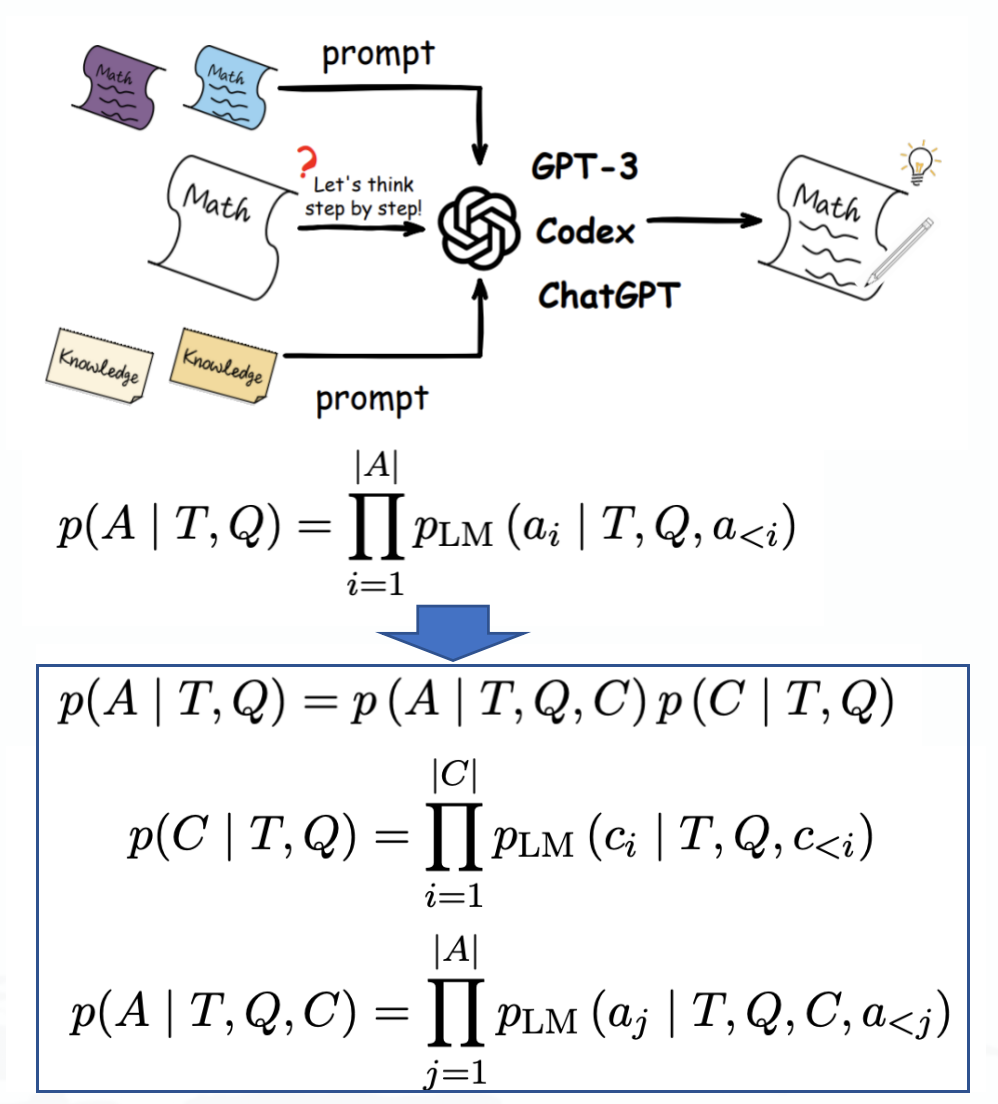
NLP任务演变
上下游任务越来越近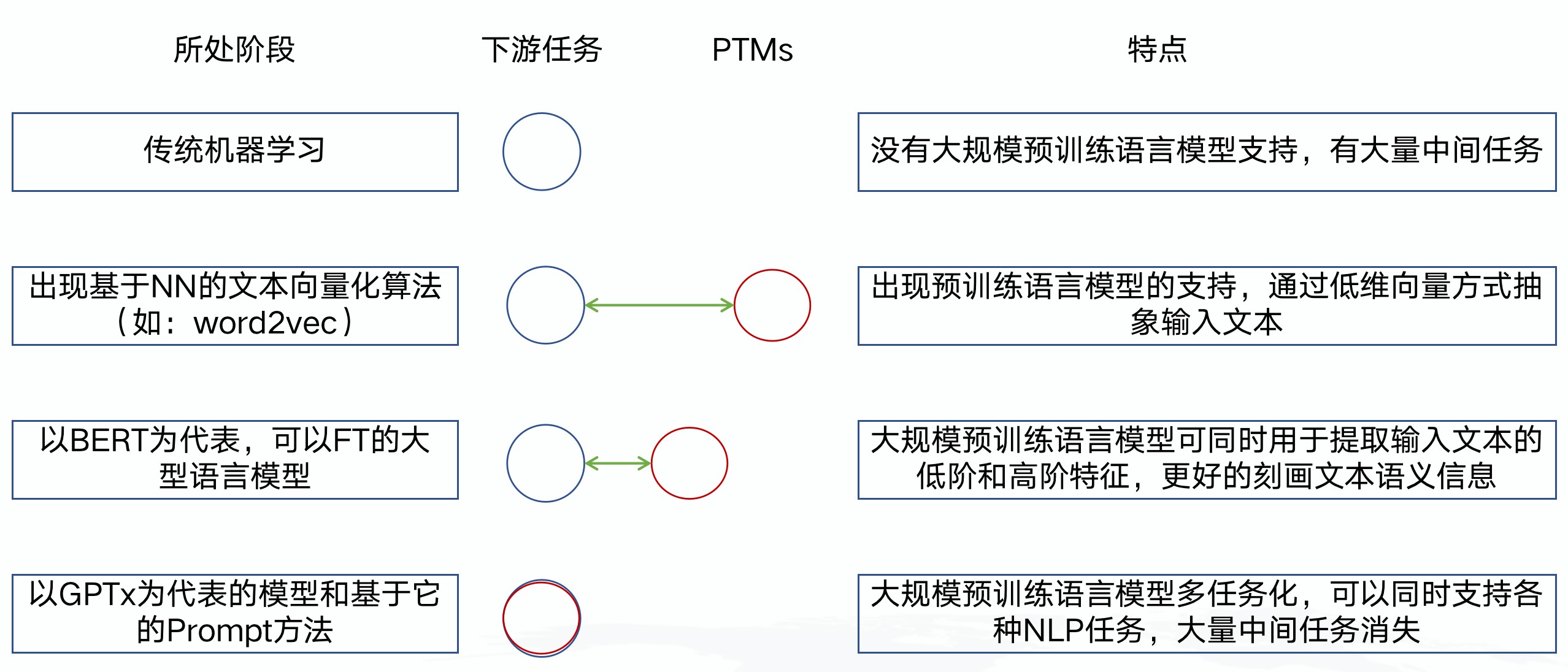
有趣的商业模式
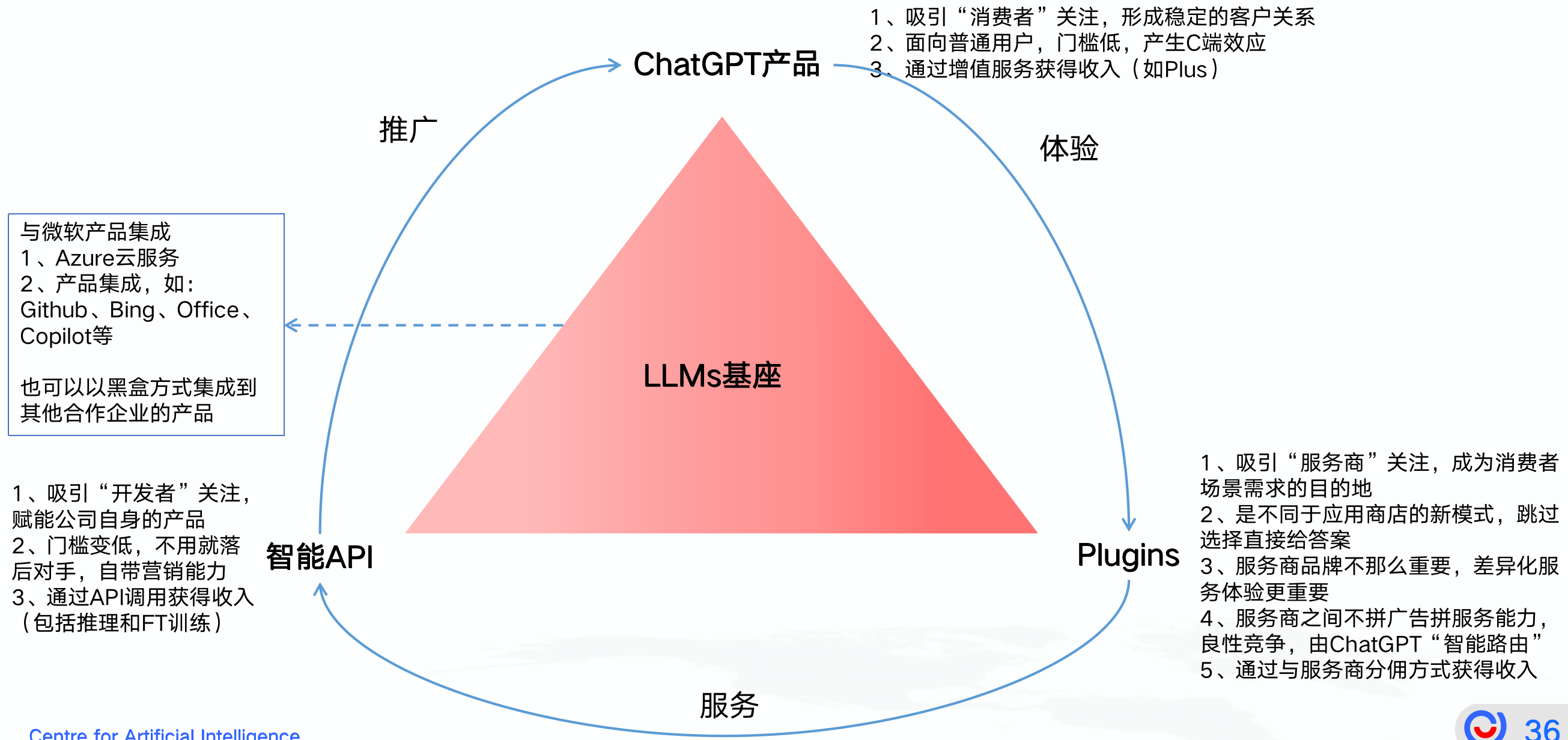
可以看到OpenAI的“生态飞轮”已经基本成型,一旦彻底站稳,其他公司想要追赶会很难,所以像Google这样的巨头一定是非常焦虑,先不说大模型效果能否和GPT-4相比,即使更好,生态上慢了也就落后了,就像当年Google通过长尾建立的以广告为中心的生态模式,OpenAI将会是一种新的生态模式。
总结
1、LLMs的头部垄断越来越明显,机会更多的在垂直领域,Prompt技术让我们更好的发挥其潜力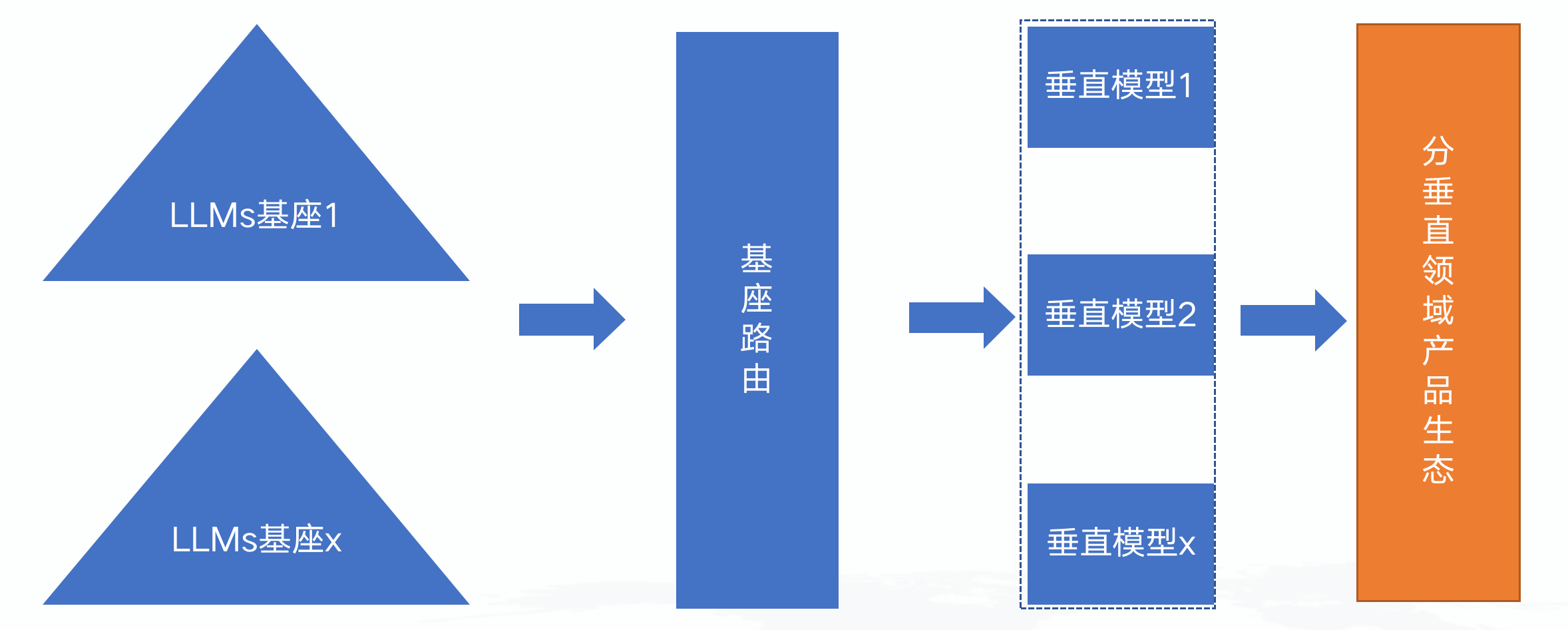
2、LLMs的下一个阶段会往通用性更强,多模态、多任务能力更强的方向发展,向AGI飞奔 3、LLMs未来的复杂逻辑推理能力、数学能力会越来越强,或通过plugins解决,通吃CV、NLP 4、大规模、高质量的数据依然会是LLMs的核心竞争力及提升效果的保障 5、大公司围绕LLMs工程化,底层训练架构和推理架构基础能力的比拼会更厉害,英伟达会很开心 6、模型同质化竞争加剧,内卷会越来越厉害,产品创新更重要 7、几乎每个职业都会收到冲击,pros:真的能提高效率,cons:人真的会被代替